In which of the following scenarios is lasso regression preferable over ridge regression?
When working with textual data and trying to classify text into different languages, which approach to representing features makes the most sense?
Which of the following is the primary purpose of hyperparameter optimization?
Workflow design patterns for the machine learning pipelines:
Which of the following describes a benefit of machine learning for solving business problems?
For each of the last 10 years, your team has been collecting data from a group of subjects, including their age and numerous biomarkers collected from blood samples. You are tasked with creating a prediction model of age using the biomarkers as input. You start by performing a linear regression using all of the data over the 10-year period, with age as the dependent variable and the biomarkers as predictors.
Which assumption of linear regression is being violated?
You have a dataset with thousands of features, all of which are categorical. Using these features as predictors, you are tasked with creating a prediction model to accurately predict the value of a continuous dependent variable. Which of the following would be appropriate algorithms to use? (Select two.)
Which of the following text vectorization methods is appropriate and correctly defined for an English-to-Spanish translation machine?
Which of the following is TRUE about SVM models?
Your dependent variable Y is a count, ranging from 0 to infinity. Because Y is approximately log-normally distributed, you decide to log-transform the data prior to performing a linear regression.
What should you do before log-transforming Y?
A product manager is designing an Artificial Intelligence (AI) solution and wants to do so responsibly, evaluating both positive and negative outcomes.
The team creates a shared taxonomy of potential negative impacts and conducts an assessment along vectors such as severity, impact, frequency, and likelihood.
Which modeling technique does this team use?
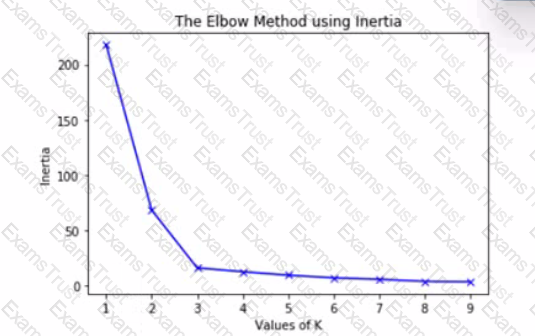
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Which of the following methods can be used to rebalance a dataset using the rebalance design pattern?
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
Which two of the following decrease technical debt in ML systems? (Select two.)
Why do data skews happen in the ML pipeline?
A company is developing a merchandise sales application The product team uses training data to teach the AI model predicting sales, and discovers emergent bias. What caused the biased results?
A big data architect needs to be cautious about personally identifiable information (PII) that may be captured with their new IoT system. What is the final stage of the Data Management Life Cycle, which the architect must complete in order to implement data privacy and security appropriately?
In general, models that perform their tasks:
Which of the following regressions will help when there is the existence of near-linear relationships among the independent variables (collinearity)?
You are developing a prediction model. Your team indicates they need an algorithm that is fast and requires low memory and low processing power. Assuming the following algorithms have similar accuracy on your data, which is most likely to be an ideal choice for the job?
Which three security measures could be applied in different ML workflow stages to defend them against malicious activities? (Select three.)
Which of the following sentences is true about model evaluation and model validation in ML pipelines?
A change in the relationship between the target variable and input features is
Which of the following items should be included in a handover to the end user to enable them to use and run a trained model on their own system? (Select three.)
When should you use semi-supervised learning? (Select two.)
Which of the following sentences is TRUE about the definition of cloud models for machine learning pipelines?