A data analysis team is working with the table_bronze SQL table as a source for one of its most complex projects. A stakeholder of the project notices that some of the downstream data is duplicative. The analysis team identifies table_bronze as the source of the duplication.
Which of the following queries can be used to deduplicate the data from table_bronze and write it to a new table table_silver?
A)
CREATE TABLE table_silver AS
SELECT DISTINCT *
FROM table_bronze;
B)
CREATE TABLE table_silver AS
INSERT *
FROM table_bronze;
C)
CREATE TABLE table_silver AS
MERGE DEDUPLICATE *
FROM table_bronze;
D)
INSERT INTO TABLE table_silver
SELECT * FROM table_bronze;
E)
INSERT OVERWRITE TABLE table_silver
SELECT * FROM table_bronze;
A data engineering team has created a Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables. The microbatches are triggered every minute.
A data analyst has created a dashboard based on this gold-level data. The project stakeholders want to see the results in the dashboard updated within one minute or less of new data becoming available within the gold-level tables.
Which of the following cautions should the data analyst share prior to setting up the dashboard to complete this task?
A business analyst has been asked to create a data entity/object called sales_by_employee. It should always stay up-to-date when new data are added to the sales table. The new entity should have the columns sales_person, which will be the name of the employee from the employees table, and sales, which will be all sales for that particular sales person. Both the sales table and the employees table have an employee_id column that is used to identify the sales person.
Which of the following code blocks will accomplish this task?
A)

B)

C)
D)

A data analyst is processing a complex aggregation on a table with zero null values and their query returns the following result:
Which of the following queries did the analyst run to obtain the above result?
A)
B)
C)
D)
E)

Which location can be used to determine the owner of a managed table?
Which statement about subqueries is correct?
Which of the following approaches can be used to ingest data directly from cloud-based object storage?
A data analyst has been asked to provide a list of options on how to share a dashboard with a client. It is a security requirement that the client does not gain access to any other information, resources, or artifacts in the database.
Which of the following approaches cannot be used to share the dashboard and meet the security requirement?
A data analyst wants the following output:
customer_name
number_of_orders
John Doe
388
Zhang San
234
Which statement will produce this output?
Which statement describes descriptive statistics?
Where in the Databricks SQL workspace can a data analyst configure a refresh schedule for a query when the query is not attached to a dashboard or alert?
Which of the following benefits of using Databricks SQL is provided by Data Explorer?
A data analyst has created a user-defined function using the following line of code:
CREATE FUNCTION price(spend DOUBLE, units DOUBLE)
RETURNS DOUBLE
RETURN spend / units;
Which of the following code blocks can be used to apply this function to the customer_spend and customer_units columns of the table customer_summary to create column customer_price?
In which of the following situations will the mean value and median value of variable be meaningfully different?
A data analyst created and is the owner of the managed table my_ table. They now want to change ownership of the table to a single other user using Data Explorer.
Which of the following approaches can the analyst use to complete the task?
The stakeholders.customers table has 15 columns and 3,000 rows of data. The following command is run:
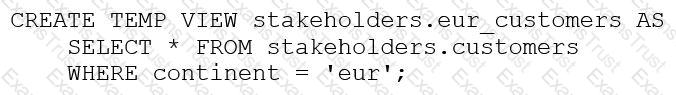
After runningSELECT * FROM stakeholders.eur_customers, 15 rows are returned. After the command executes completely, the user logs out of Databricks.
After logging back in two days later, what is the status of thestakeholders.eur_customersview?
Which of the following approaches can be used to connect Databricks to Fivetran for data ingestion?
A data engineering team has created a Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables. The microbatches are triggered every 10 minutes.
A data analyst has created a dashboard based on this gold level data. The project stakeholders want to see the results in the dashboard updated within 10 minutes or less of new data becoming available within the gold-level tables.
What is the ability to ensure the streamed data is included in the dashboard at the standard requested by the project stakeholders?
A data analyst runs the following command:
INSERT INTO stakeholders.suppliers TABLE stakeholders.new_suppliers;
What is the result of running this command?