Red Hat OpenShifl GitOps organizes the deployment process around repositories. It always has at least two repositories, an Application repository with the source code and what other repository?
Nexus
Ansible configuration
Environment configuration
Maven
In Red Hat OpenShift GitOps, which is based on ArgoCD, the deployment process is centered around Git repositories. The framework typically uses at least two repositories:
Application Repository – Contains the source code, manifests, and configurations for the application itself.
Environment Configuration Repository (Correct Answer) – Stores Kubernetes/OpenShift manifests, Helm charts, Kustomize overlays, or other deployment configurations for different environments (e.g., Dev, Test, Prod).
This separation of concerns ensures that:
Developers manage application code separately from infrastructure and deployment settings.
GitOps principles are applied, enabling automated deployments based on repository changes.
The Environment Configuration Repository serves as the single source of truth for deployment configurations.
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. Nexus
❌ Incorrect – Nexus is a repository manager for storing binaries, artifacts, and dependencies (e.g., Docker images, JAR files), but it is not a GitOps repository.
❌
B. Ansible configuration
❌ Incorrect – While Ansible can manage infrastructure automation, OpenShift GitOps primarily uses Kubernetes manifests, Helm, or Kustomize for deployment configurations.
❌
D. Maven
❌ Incorrect – Maven is a build automation tool for Java applications, not a repository type used in GitOps workflows.
❌
Final Answer:✅ C. Environment configuration
Red Hat OpenShift GitOps Documentation
IBM Cloud Pak for Integration and OpenShift GitOps
ArgoCD Best Practices for GitOps
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which CLI command will retrieve the logs from a pod?
oc get logs ...
oc logs ...
oc describe ...
oc retrieve logs ...
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, administrators often need to retrieve logs from pods to diagnose issues or monitor application behavior. The correct OpenShift CLI (oc) command to retrieve logs from a specific pod is:
sh
CopyEdit
oc logs
This command fetches the logs of a running container within the specified pod. If a pod has multiple containers, the -c flag is used to specify the container name:
sh
CopyEdit
oc logs
A. oc get logs → Incorrect. The oc get command is used to list resources (such as pods, deployments, etc.), but it does not retrieve logs.
C. oc describe → Incorrect. This command provides detailed information about a pod, including events and status, but not logs.
D. oc retrieve logs → Incorrect. There is no such command in OpenShift CLI.
IBM Cloud Pak for Integration Logging and Monitoring
Red Hat OpenShift CLI (oc) Reference
IBM Cloud Pak for Integration Troubleshooting
Explanation of Other Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Starling with Common Services 3.6, which two monitoring service modes are available?
OCP Monitoring
OpenShift Common Monitoring
C CP4I Monitoring
CS Monitoring
Grafana Monitoring
Starting with IBM Cloud Pak for Integration (CP4I) v2021.2, which uses IBM Common Services 3.6, there are two monitoring service modes available for tracking system health and performance:
OCP Monitoring (OpenShift Container Platform Monitoring) – This is the native OpenShift monitoring system that provides observability for the entire cluster, including nodes, pods, and application workloads. It uses Prometheus for metrics collection and Grafana for visualization.
CS Monitoring (Common Services Monitoring) – This is the IBM Cloud Pak for Integration-specific monitoring service, which provides additional observability features specifically for IBM Cloud Pak components. It integrates with OpenShift but focuses on Cloud Pak services and applications.
Option B (OpenShift Common Monitoring) is incorrect: While OpenShift has a Common Monitoring Stack, it is not a specific mode for IBM CP4I monitoring services. Instead, it is a subset of OCP Monitoring used for monitoring the OpenShift control plane.
Option C (CP4I Monitoring) is incorrect: There is no separate "CP4I Monitoring" service mode. CP4I relies on OpenShift's monitoring framework and IBM Common Services monitoring.
Option E (Grafana Monitoring) is incorrect: Grafana is a visualization tool, not a standalone monitoring service mode. It is used in conjunction with Prometheus in both OCP Monitoring and CS Monitoring.
IBM Cloud Pak for Integration Monitoring Documentation
IBM Common Services Monitoring Overview
OpenShift Monitoring Stack – Red Hat Documentation
Why the other options are incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Where is the initial admin password stored during an installation of IBM Cloud Pak for Integration?
platform-auth-idp-credentials. in the 1AM service installation folder.
platform-auth-idp-credentials, in the ibm-common-services namespace.
platform-auth-idp-credentials, in the /sbin folder.
platform-auth-idp-credentials. in the master-node root folder.
During the installation of IBM Cloud Pak for Integration (CP4I), an initial admin password is automatically generated and securely stored in a Kubernetes secret called platform-auth-idp-credentials.
This secret is located in the ibm-common-services namespace, which is a central namespace used by IBM Cloud Pak Foundational Services to manage authentication, identity providers, and security.
The stored credentials are required for initial login to the IBM Cloud Pak platform and can be retrieved using OpenShift CLI (oc).
Retrieving the Initial Admin Password:To view the stored credentials, administrators can run the following command:
sh
Copy
oc get secret platform-auth-idp-credentials -n ibm-common-services -o jsonpath='{.data.admin_password}' | base64 --decode
This will decode and display the initial admin password.
A. platform-auth-idp-credentials in the IAM service installation folder (Incorrect)
The IAM (Identity and Access Management) service does store authentication-related configurations, but the admin password is specifically stored in a Kubernetes secret, not in a local file.
C. platform-auth-idp-credentials in the /sbin folder (Incorrect)
The /sbin folder is a system directory on Linux-based OSes, and IBM Cloud Pak for Integration does not store authentication credentials there.
D. platform-auth-idp-credentials in the master-node root folder (Incorrect)
IBM Cloud Pak stores authentication credentials securely within Kubernetes secrets, not directly in the root folder of the master node.
Analysis of Incorrect Options:
IBM Cloud Pak for Integration - Retrieving Admin Credentials
IBM Cloud Pak Foundational Services - Managing Secrets
Red Hat OpenShift - Managing Kubernetes Secrets
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two App Connect resources enable callable flows to be processed between an integration solution in a cluster and an integration server in an on-premise system?
Sync server
Connectivity agent
Kafka sync
Switch server
Routing agent
In IBM App Connect, which is part of IBM Cloud Pak for Integration (CP4I), callable flows enable integration between different environments, including on-premises systems and cloud-based integration solutions deployed in an OpenShift cluster.
To facilitate this connectivity, two critical resources are used:
The Connectivity Agent acts as a bridge between cloud-hosted App Connect instances and on-premises integration servers.
It enables secure bidirectional communication by allowing callable flows to connect between cloud-based and on-premise integration servers.
This is essential for hybrid cloud integrations, where some components remain on-premises for security or compliance reasons.
The Routing Agent directs incoming callable flow requests to the appropriate App Connect integration server based on configured routing rules.
It ensures low-latency and efficient message routing between cloud and on-premise systems, making it a key component for hybrid integrations.
1. Connectivity Agent (✅ Correct Answer)2. Routing Agent (✅ Correct Answer)
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. Sync server
❌ Incorrect – There is no "Sync Server" component in IBM App Connect. Synchronization happens through callable flows, but not via a "Sync Server".
❌
C. Kafka sync
❌ Incorrect – Kafka is used for event-driven messaging, but it is not required for callable flows between cloud and on-premises environments.
❌
D. Switch server
❌ Incorrect – No such component called "Switch Server" exists in App Connect.
❌
Final Answer:✅ B. Connectivity agent✅ E. Routing agent
IBM App Connect - Callable Flows Documentation
IBM Cloud Pak for Integration - Hybrid Connectivity with Connectivity Agents
IBM App Connect Enterprise - On-Premise and Cloud Integration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which OpenShift component controls the placement of workloads on nodes for Cloud Pak for Integration deployments?
API Server
Controller Manager
Etcd
Scheduler
In IBM Cloud Pak for Integration (CP4I) v2021.2, which runs on Red Hat OpenShift, the component responsible for determining the placement of workloads (pods) on worker nodes is the Scheduler.
API Server (Option A): The API Server is the front-end of the OpenShift and Kubernetes control plane, handling REST API requests, authentication, and cluster state updates. However, it does not decide where workloads should be placed.
Controller Manager (Option B): The Controller Manager ensures the desired state of the system by managing controllers (e.g., ReplicationController, NodeController). It does not handle pod placement.
Etcd (Option C): Etcd is the distributed key-value store used by OpenShift and Kubernetes to store cluster state data. It plays no role in scheduling workloads.
Scheduler (Option D - Correct Answer): The Scheduler is responsible for selecting the most suitable node to run a newly created pod based on resource availability, affinity/anti-affinity rules, and other constraints.
When a new pod is created, it initially has no assigned node.
The Scheduler evaluates all worker nodes and assigns the pod to the most appropriate node, ensuring balanced resource utilization and policy compliance.
In CP4I, efficient workload placement is crucial for maintaining performance and resilience, and the Scheduler ensures that workloads are optimally distributed across the cluster.
Explanation of OpenShift Components:Why the Scheduler is Correct?IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM CP4I Documentation – Deploying on OpenShift
Red Hat OpenShift Documentation – Understanding the Scheduler
Kubernetes Documentation – Scheduler
If the App Connect Operator is installed in a restricted network, which statement is true?
Simple Storage Service (S3) can not be used for BAR files.
Ephemeral storage can not be used for BAR files.
Only Ephemeral storage is supported for BAR files.
Persistent Claim storage can not be used for BAR files.
In IBM Cloud Pak for Integration (CP4I) v2021.2, when App Connect Operator is deployed in a restricted network (air-gapped environment), access to external cloud-based services (such as AWS S3) is typically not available.
A restricted network means no direct internet access, so external storage services like Amazon S3 cannot be used to store Broker Archive (BAR) files.
BAR files contain packaged integration flows for IBM App Connect Enterprise (ACE).
In restricted environments, administrators must use internal storage options, such as:
Persistent Volume Claims (PVCs)
Ephemeral storage (temporary, in-memory storage)
Why Option A (S3 Cannot Be Used) is Correct:
B. Ephemeral storage cannot be used for BAR files. → Incorrect
Ephemeral storage is supported but is not recommended for production because data is lost when the pod restarts.
C. Only Ephemeral storage is supported for BAR files. → Incorrect
Both Ephemeral storage and Persistent Volume Claims (PVCs) are supported for storing BAR files.
Ephemeral storage is not the only option.
D. Persistent Claim storage cannot be used for BAR files. → Incorrect
Persistent Volume Claims (PVCs) are a supported and recommended method for storing BAR files in a restricted network.
This ensures that integration flows persist even if a pod is restarted or redeployed.
Explanation of Incorrect Answers:
IBM App Connect Enterprise - BAR File Storage Options
IBM Cloud Pak for Integration Storage Considerations
IBM Cloud Pak for Integration Deployment in Restricted Environments
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
An administrator has just installed the OpenShift cluster as the first step of installing Cloud Pak for Integration.
What is an indication of successful completion of the OpenShift Cluster installation, prior to any other cluster operation?
The command "which oc" shows that the OpenShift Command Line Interface(oc) is successfully installed.
The duster credentials are included at the end of the /.openshifl_install.log file.
The command "oc get nodes" returns the list of nodes in the cluster.
The OpenShift Admin console can be opened with the default user and will display the cluster statistics.
After successfully installing an OpenShift cluster, the most reliable way to confirm that the cluster is up and running is by checking the status of its nodes. This is done using the oc get nodes command.
The command oc get nodes lists all the nodes in the cluster and their current status.
If the installation is successful, the nodes should be in a "Ready" state, indicating that the cluster is functional and prepared for further configuration, including the installation of IBM Cloud Pak for Integration (CP4I).
Option A (Incorrect – which oc): This only verifies that the OpenShift CLI (oc) is installed on the local system, but it does not confirm the cluster installation.
Option B (Incorrect – Checking /.openshift_install.log): While the installation log may indicate a successful install, it does not confirm the operational status of the cluster.
Option C (Correct – oc get nodes): This command confirms that the cluster is running and provides a status check on all nodes. If the nodes are listed and marked as "Ready", it indicates that the OpenShift cluster is successfully installed.
Option D (Incorrect – OpenShift Admin Console Access): While the OpenShift Web Console can be accessed if the cluster is installed, this does not guarantee that the cluster is fully operational. The most definitive check is through the oc get nodes command.
Analysis of the Options:
IBM Cloud Pak for Integration Installation Guide
Red Hat OpenShift Documentation – Cluster Installation
Verifying OpenShift Cluster Readiness (oc get nodes)
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement is true about enabling open tracing for API Connect?
Only APIs using API Gateway can be traced in the Operations Dashboard.
API debug data is made available in OpenShift cluster logging.
This feature is only available in non-production deployment profiles
Trace data can be viewed in Analytics dashboards
Open Tracing in IBM API Connect allows for distributed tracing of API calls across the system, helping administrators analyze performance bottlenecks and troubleshoot issues. However, this capability is specifically designed to work with APIs that utilize the API Gateway.
Option A (Correct Answer): IBM API Connect integrates with OpenTracing for API Gateway, allowing the tracing of API requests in the Operations Dashboard. This provides deep visibility into request flows and latencies.
Option B (Incorrect): API debug data is not directly made available in OpenShift cluster logging. Instead, API tracing data is captured using OpenTracing-compatible tools.
Option C (Incorrect): OpenTracing is available for all deployment profiles, including production, not just non-production environments.
Option D (Incorrect): Trace data is not directly visible in Analytics dashboards but rather in the Operations Dashboard where administrators can inspect API request traces.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM API Connect Documentation – OpenTracing
IBM Cloud Pak for Integration - API Gateway Tracing
IBM API Connect Operations Dashboard Guide
Which OpenShift component is responsible for checking the OpenShift Update Service for valid updates?
Cluster Update Operator
Cluster Update Manager
Cluster Version Updater
Cluster Version Operator
The Cluster Version Operator (CVO) is responsible for checking the OpenShift Update Service (OSUS) for valid updates in an OpenShift cluster. It continuously monitors for available updates and ensures that the cluster components are updated according to the specified update policy.
Periodically checks the OpenShift Update Service (OSUS) for available updates.
Manages the ClusterVersion resource, which defines the current version and available updates.
Ensures that cluster operators are applied in the correct order.
Handles update rollouts and recovery in case of failures.
A. Cluster Update Operator – No such component exists in OpenShift.
B. Cluster Update Manager – This is not an OpenShift component. The update process is managed by CVO.
C. Cluster Version Updater – Incorrect term; the correct term is Cluster Version Operator (CVO).
IBM Documentation – OpenShift Cluster Version Operator
IBM Cloud Pak for Integration (CP4I) v2021.2 Knowledge Center
Red Hat OpenShift Documentation on Cluster Updates
Key Functions of the Cluster Version Operator (CVO):Why Not the Other Options?IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References.
What protocol is used for secure communications between the IBM Cloud Pak for Integration module and any other capability modules installed in the cluster using the Platform Navigator?
SSL
HTTP
SSH
TLS
In IBM Cloud Pak for Integration (CP4I) v2021.2, secure communication between the Platform Navigator and other capability modules (such as API Connect, MQ, App Connect, and Event Streams) is essential to maintain data integrity and confidentiality.
The protocol used for secure communications between CP4I modules is Transport Layer Security (TLS).
Encryption: TLS encrypts data during transmission, preventing unauthorized access.
Authentication: TLS ensures that modules communicate securely by verifying identities using certificates.
Data Integrity: TLS protects data from tampering while in transit.
Industry Standard: TLS is the modern, secure successor to SSL and is widely adopted in enterprise security.
Why TLS is Used for Secure Communications in CP4I?By default, CP4I services use TLS 1.2 or higher, ensuring strong encryption for inter-service communication within the OpenShift cluster.
IBM Cloud Pak for Integration enforces TLS-based encryption for internal and external communications.
TLS provides a secure channel for communication between Platform Navigator and other CP4I components.
It is the recommended protocol over SSL due to security vulnerabilities in older SSL versions.
Why Answer D (TLS) is Correct?
A. SSL → Incorrect
SSL (Secure Sockets Layer) is an older protocol that has been deprecated due to security flaws.
CP4I uses TLS, which is the successor to SSL.
B. HTTP → Incorrect
HTTP is not secure for internal communication.
CP4I uses HTTPS (HTTP over TLS) for secure connections.
C. SSH → Incorrect
SSH (Secure Shell) is used for remote administration, not for service-to-service communication within CP4I.
CP4I services do not use SSH for inter-service communication.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration Security Guide
Transport Layer Security (TLS) in IBM Cloud Paks
IBM Platform Navigator Overview
TLS vs SSL Security Comparison
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is the License Service's frequency of refreshing data?
1 hour.
30 seconds.
5 minutes.
30 minutes.
In IBM Cloud Pak Foundational Services, the License Service is responsible for collecting, tracking, and reporting license usage data. It ensures compliance by monitoring the consumption of IBM Cloud Pak licenses across the environment.
The License Service refreshes its data every 5 minutes to keep the license usage information up to date.
This frequent update cycle helps organizations maintain accurate tracking of their entitlements and avoid non-compliance issues.
A. 1 hour (Incorrect)
The License Service updates its records more frequently than every hour to provide timely insights.
B. 30 seconds (Incorrect)
A refresh interval of 30 seconds would be too frequent for license tracking, leading to unnecessary overhead.
C. 5 minutes (Correct)
The IBM License Service refreshes its data every 5 minutes, ensuring real-time tracking without excessive system load.
D. 30 minutes (Incorrect)
A 30-minute refresh would delay the reporting of license usage, which is not the actual behavior of the License Service.
Analysis of the Options:
IBM License Service Overview
IBM Cloud Pak License Service Data Collection Interval
IBM Cloud Pak Compliance and License Reporting
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
When upgrading Cloud Pak (or Integration and switching from Common Services (CS) monitoring to OpenShift monitoring, what command will check whether CS monitoring is enabled?
oc get pods -n ibm-common-services | grep monitoring
oc list pods -A | grep -i monitoring
oc describe pods/ibm-common-services | grep monitoring
oc get containers -A
When upgrading IBM Cloud Pak for Integration (CP4I) and switching from Common Services (CS) monitoring to OpenShift monitoring, it is crucial to determine whether CS monitoring is currently enabled.
The correct command to check this is:
sh
CopyEdit
oc get pods -n ibm-common-services | grep monitoring
This command (oc get pods -n ibm-common-services) lists all pods in the ibm-common-services namespace, which is where IBM Common Services (including monitoring components) are deployed.
Using grep monitoring filters the output to show only the monitoring-related pods.
If monitoring-related pods are running in this namespace, it confirms that CS monitoring is enabled.
B (oc list pods -A | grep -i monitoring) – Incorrect
The oc list pods command does not exist in OpenShift CLI. The correct command to list all pods across all namespaces is oc get pods -A.
C (oc describe pods/ibm-common-services | grep monitoring) – Incorrect
oc describe pods/ibm-common-services is not a valid OpenShift command. The correct syntax would be oc describe pod
D (oc get containers -A) – Incorrect
The oc get containers command is not valid in OpenShift CLI. Instead, oc get pods -A lists all pods, but it does not specifically filter monitoring-related services in the ibm-common-services namespace.
Explanation of Incorrect Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Documentation: Monitoring IBM Cloud Pak foundational services
IBM Cloud Pak for Integration: Disabling foundational services monitoring
OpenShift Documentation: Managing Pods in OpenShift
What is the outcome when the API Connect operator is installed at the cluster scope?
Automatic updates will be restricted by the approval strategy.
API Connect services will be deployed in the default namespace.
The operator installs in a production deployment profile.
The entire cluster effectively behaves as one large tenant.
When the API Connect operator is installed at the cluster scope, it means that the operator has permissions and visibility across the entire Kubernetes or OpenShift cluster, rather than being limited to a single namespace. This setup allows multiple namespaces to utilize the API Connect resources, effectively making the entire cluster behave as one large tenant.
Cluster-wide installation enables shared services across multiple namespaces, ensuring that API management is centralized.
Multi-tenancy behavior occurs because all API Connect components, such as the Gateway, Analytics, and Portal, can serve multiple teams or applications within the cluster.
Operator Lifecycle Manager (OLM) governs how the API Connect operator is deployed and managed across namespaces, reinforcing the unified behavior across the cluster.
IBM API Connect Operator Documentation
IBM Cloud Pak for Integration - Installing API Connect
IBM Redbook - Cloud Pak for Integration Architecture Guide
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What ate the two possible options to upgrade Common Services from the Extended Update Support (EUS) version (3.6.x) to the continuous delivery versions (3.7.x or later)?
Click the Update button on the Details page of the common-services operand.
Select the Update Common Services option from the Cloud Pak Administration Hub console.
Use the OpenShift web console to change the operator channel from stable-v1 to v3.
Run the script provided by IBM using links available in the documentation.
Click the Update button on the Details page of the IBM Cloud Pak Founda-tional Services operator.
IBM Cloud Pak for Integration (CP4I) v2021.2 relies on IBM Cloud Pak Foundational Services, which was previously known as IBM Common Services. Upgrading from the Extended Update Support (EUS) version (3.6.x) to a continuous delivery version (3.7.x or later) requires following IBM's recommended upgrade paths. The two valid options are:
Using IBM's provided script (Option D):
IBM provides a script specifically designed to upgrade Cloud Pak Foundational Services from an EUS version to a later continuous delivery (CD) version.
This script automates the necessary upgrade steps and ensures dependencies are properly handled.
IBM's official documentation includes the script download links and usage instructions.
Using the IBM Cloud Pak Foundational Services operator update button (Option E):
The IBM Cloud Pak Foundational Services operator in the OpenShift web console provides an update button that allows administrators to upgrade services.
This method is recommended by IBM for in-place upgrades, ensuring minimal disruption while moving from 3.6.x to a later version.
The upgrade process includes rolling updates to maintain high availability.
Option A (Click the Update button on the Details page of the common-services operand):
There is no direct update button at the operand level that facilitates the entire upgrade from EUS to CD versions.
The upgrade needs to be performed at the operator level, not just at the operand level.
Option B (Select the Update Common Services option from the Cloud Pak Administration Hub console):
The Cloud Pak Administration Hub does not provide a direct update option for Common Services.
Updates are handled via OpenShift or IBM’s provided scripts.
Option C (Use the OpenShift web console to change the operator channel from stable-v1 to v3):
Simply changing the operator channel does not automatically upgrade from an EUS version to a continuous delivery version.
IBM requires following specific upgrade steps, including running a script or using the update button in the operator.
Incorrect Options and Justification:
IBM Cloud Pak Foundational Services Upgrade Documentation:
IBM Official Documentation
IBM Cloud Pak for Integration v2021.2 Knowledge Center
IBM Redbooks and Technical Articles on CP4I Administration
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
How can OLM be triggered to start upgrading the IBM Cloud Pak for Integration Platform Navigator operator?
Navigate to the Installed Operators, select the Platform Navigator operator and click the Upgrade button on the Details page.
Navigate to the Installed Operators, select the Platform Navigator operator, select the operand instance, and select Upgrade from the Actions list.
Navigate to the Installed Operators, select the Platform Navigator operator and select the latest channel version on the Subscription tab.
Open the Platform Navigator web interface and select Update from the main menu. In IBM Cloud Pak for Integration (CP4I) v2021.2, the Operator Lifecycle Manager (OLM) manages operator upgrades in OpenShift. The IBM Cloud Pak Platform Navigator operator is updated through the OLM subscription mechanism, which controls how updates are applied.
Correct Answer: CTo trigger OLM to start upgrading the Platform Navigator operator, follow thes
When using the Platform Navigator, what permission is required to add users and user groups?
root
Super-user
Administrator
User
In IBM Cloud Pak for Integration (CP4I) v2021.2, the Platform Navigator is the central UI for managing integration capabilities, including user and access control. To add users and user groups, the required permission level is Administrator.
User Management Capabilities:
The Administrator role in Platform Navigator has full access to user and group management functions, including:
Adding new users
Assigning roles
Managing access policies
RBAC (Role-Based Access Control) Enforcement:
CP4I enforces RBAC to restrict actions based on roles.
Only Administrators can modify user access, ensuring security compliance.
Access Control via OpenShift and IAM Integration:
User management in CP4I integrates with IBM Cloud IAM or OpenShift User Management.
The Administrator role ensures correct permissions for authentication and authorization.
Why is "Administrator" the Correct Answer?
Why Not the Other Options?Option
Reason for Exclusion
A. root
"root" is a Linux system user and not a role in Platform Navigator. CP4I does not grant UI-based root access.
B. Super-user
No predefined "Super-user" role exists in CP4I. If referring to an elevated user, it still does not match the Administrator role in Platform Navigator.
D. User
Regular "User" roles have view-only or limited permissions and cannot manage users or groups.
Thus, the Administrator role is the correct choice for adding users and user groups in Platform Navigator.
IBM Cloud Pak for Integration - Platform Navigator Overview
Managing Users in Platform Navigator
Role-Based Access Control in CP4I
OpenShift User Management and Authentication
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which two storage types are required before installing Automation Assets?
Asset data storage - a File RWX volume
Asset metadata storage - a Block RWO volume
Asset ephemeral storage - a Block RWX volume
Automation data storage - a Block RWO volume
Automation metadata storage - a File RWX volume
Before installing Automation Assets in IBM Cloud Pak for Integration (CP4I) v2021.2, specific storage types must be provisioned to support asset data and metadata storage. These storage types are required to ensure proper functioning and persistence of Automation Assets in an OpenShift-based deployment.
Asset Data Storage (File RWX Volume)
This storage is used to store asset files, which need to be accessible by multiple pods simultaneously.
It requires a shared file storage with ReadWriteMany (RWX) access mode, ensuring multiple replicas can access the data.
Example: NFS (Network File System) or OpenShift persistent storage supporting RWX.
Asset Metadata Storage (Block RWO Volume)
This storage is used for managing metadata related to automation assets.
It requires a block storage with ReadWriteOnce (RWO) access mode, which ensures exclusive access by a single node at a time for consistency.
Example: IBM Cloud Block Storage, OpenShift Container Storage (OCS) with RWO mode.
C. Asset ephemeral storage - a Block RWX volume (Incorrect)
There is no requirement for ephemeral storage in Automation Assets. Persistent storage is necessary for both asset data and metadata.
D. Automation data storage - a Block RWO volume (Incorrect)
Automation Assets specifically require file-based RWX storage for asset data, not block-based storage.
E. Automation metadata storage - a File RWX volume (Incorrect)
The metadata storage requires block-based RWO storage, not file-based RWX storage.
IBM Cloud Pak for Integration Documentation: Automation Assets Storage Requirements
IBM OpenShift Storage Documentation: Persistent Storage Configuration
IBM Cloud Block Storage: Storage Requirements for CP4I
Explanation of Incorrect Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What is a prerequisite when configuring foundational services IAM for single-sign-on?
Access to the OpenShift Container Platform console as kubeadmin.
Access to IBM Cloud Pak for Integration as kubeadmin.
Access to OpenShift cluster as root.
Access to IAM service as administrator.
In IBM Cloud Pak for Integration (CP4I) v2021.2, Identity and Access Management (IAM) is part of Foundational Services, which provides authentication and authorization across different modules within CP4I.
When configuring IAM for single sign-on (SSO), the administrator must have administrator access to the IAM service. This is essential for:
Integrating external identity providers (IdPs) such as LDAP, SAML, or OIDC.
Managing user roles and access control policies across the Cloud Pak environment.
Configuring SSO settings for seamless authentication across all IBM Cloud Pak services.
IAM service administrators have full control over authentication and SSO settings.
They can configure and integrate identity providers for authentication.
This level of access is required to modify IAM settings in Cloud Pak for Integration.
Why Answer D (Access to IAM service as administrator) is Correct?
A. Access to the OpenShift Container Platform console as kubeadmin. → Incorrect
While kubeadmin is a cluster-wide OpenShift administrator, this role does not grant IAM administrative privileges in Cloud Pak Foundational Services.
IAM settings are managed within IBM Cloud Pak, not solely through OpenShift.
B. Access to IBM Cloud Pak for Integration as kubeadmin. → Incorrect
kubeadmin can manage OpenShift resources, but IAM requires specific access to the IAM service within Cloud Pak.
IAM administrators are responsible for configuring authentication, SSO, and identity providers.
C. Access to OpenShift cluster as root. → Incorrect
Root access is not relevant here because OpenShift does not use root users for administration.
IAM configurations are done within Cloud Pak, not at the OpenShift OS level.
Explanation of Incorrect Answers:
IBM Cloud Pak Foundational Services - IAM Configuration
Configuring Single Sign-On (SSO) in IBM Cloud Pak
IBM Cloud Pak for Integration Security Overview
OpenShift Authentication and Identity Management
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement is true about the removal of individual subsystems of API Connect on OpenShift or Cloud Pak for Integration?
They can be deleted regardless of the deployment methods.
They can be deleted if API Connect was deployed using a single top level CR.
They cannot be deleted if API Connect was deployed using a single top level CR.
They cannot be deleted if API Connect was deployed using a single top level CRM.
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying API Connect on OpenShift or within the Cloud Pak for Integration framework, there are different deployment methods:
Single Top-Level Custom Resource (CR) – This method deploys all API Connect subsystems as a single unit, meaning they are managed together. Removing individual subsystems is not supported when using this deployment method. If you need to remove a subsystem, you must delete the entire API Connect instance.
Multiple Independent Custom Resources (CRs) – This method allows more granular control, enabling the deletion of individual subsystems without affecting the entire deployment.
Since the question specifically asks about API Connect deployed using a single top-level CR, it is not possible to delete individual subsystems. The entire deployment must be deleted and reconfigured if changes are required.
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM API Connect v10 Documentation: IBM Docs - API Connect on OpenShift
IBM Cloud Pak for Integration Knowledge Center: IBM CP4I Documentation
API Connect Deployment Guide: Managing API Connect Subsystems
An administrator is looking to install Cloud Pak for Integration on an OpenShift cluster. What is the result of executing the following?
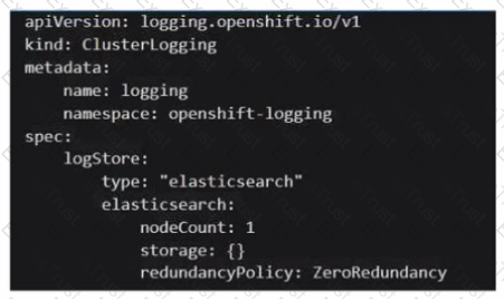
A single node ElasticSearch cluster with default persistent storage.
A single infrastructure node with persisted ElasticSearch.
A single node ElasticSearch cluster which auto scales when redundancyPolicy is set to MultiRedundancy.
A single node ElasticSearch cluster with no persistent storage.
The given YAML configuration is for ClusterLogging in an OpenShift environment, which is used for centralized logging. The key part of the specification that determines the behavior of Elasticsearch is:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 1
storage: {}
redundancyPolicy: ZeroRedundancy
nodeCount: 1
This means the Elasticsearch cluster will consist of only one node (single-node deployment).
storage: {}
The empty storage field implies no persistent storage is configured.
This means that if the pod is deleted or restarted, all stored logs will be lost.
redundancyPolicy: ZeroRedundancy
ZeroRedundancy means there is no data replication, making the system vulnerable to data loss if the pod crashes.
In contrast, a redundancy policy like MultiRedundancy ensures high availability by replicating data across multiple nodes, but that is not the case here.
Analysis of Key Fields:
Evaluating Answer Choices:Option
Explanation
Correct?
A. A single node ElasticSearch cluster with default persistent storage.
Incorrect, because storage: {} means no persistent storage is configured.
❌
B. A single infrastructure node with persisted ElasticSearch.
Incorrect, as this is not configuring an infrastructure node, and storage is not persistent.
❌
C. A single node ElasticSearch cluster which auto scales when redundancyPolicy is set to MultiRedundancy.
Incorrect, because setting MultiRedundancy does not automatically enable auto-scaling. Scaling needs manual intervention or Horizontal Pod Autoscaler (HPA).
❌
D. A single node ElasticSearch cluster with no persistent storage.
Correct, because nodeCount: 1 creates a single node, and storage: {} ensures no persistent storage.
✅
Final Answer:✅ D. A single node ElasticSearch cluster with no persistent storage.
IBM CP4I Logging and Monitoring Documentation
Red Hat OpenShift Logging Documentation
Elasticsearch Redundancy Policies in OpenShift Logging
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which of the following would contain mqsc commands for queue definitions to be executed when new MQ containers are deployed?
MORegistry
CCDTJSON
Operatorlmage
ConfigMap
In IBM Cloud Pak for Integration (CP4I) v2021.2, when deploying IBM MQ containers in OpenShift, queue definitions and other MQSC (MQ Script Command) commands need to be provided to configure the MQ environment dynamically. This is typically done using a Kubernetes ConfigMap, which allows administrators to define and inject configuration files, including MQSC scripts, into the containerized MQ instance at runtime.
A ConfigMap in OpenShift or Kubernetes is used to store configuration data as key-value pairs or files.
For IBM MQ, a ConfigMap can include an MQSC script that contains queue definitions, channel settings, and other MQ configurations.
When a new MQ container is deployed, the ConfigMap is mounted into the container, and the MQSC commands are executed to set up the queues.
Why is ConfigMap the Correct Answer?Example Usage:A sample ConfigMap containing MQSC commands for queue definitions may look like this:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-mq-config
data:
10-create-queues.mqsc: |
DEFINE QLOCAL('MY.QUEUE') REPLACE
DEFINE QLOCAL('ANOTHER.QUEUE') REPLACE
This ConfigMap can then be referenced in the MQ Queue Manager’s deployment configuration to ensure that the queue definitions are automatically executed when the MQ container starts.
A. MORegistry - Incorrect
The MORegistry is not a component used for queue definitions. Instead, it relates to Managed Objects in certain IBM middleware configurations.
B. CCDTJSON - Incorrect
CCDTJSON refers to Client Channel Definition Table (CCDT) in JSON format, which is used for defining MQ client connections rather than queue definitions.
C. OperatorImage - Incorrect
The OperatorImage contains the IBM MQ Operator, which manages the lifecycle of MQ instances in OpenShift, but it does not store queue definitions or execute MQSC commands.
IBM Documentation: Configuring IBM MQ with ConfigMaps
IBM MQ Knowledge Center: Using MQSC commands in Kubernetes ConfigMaps
IBM Redbooks: IBM Cloud Pak for Integration Deployment Guide
Analysis of Other Options:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
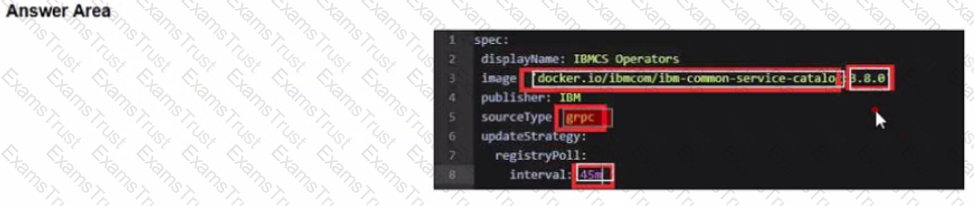
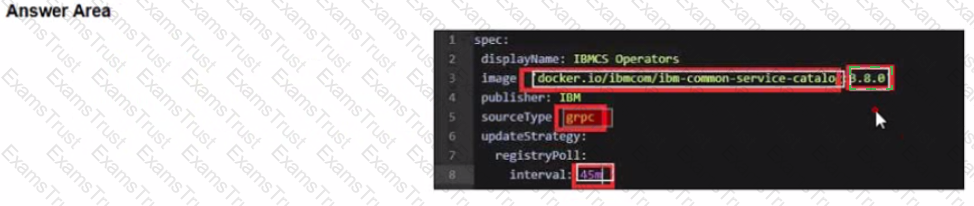
Before upgrading the Foundational Services installer version, the installer catalog source image must have the correct tag. To always use the latest catalog click on where the text 'latest' should be inserted into the image below?
Upgrading from version 3.4.x and 3.5.x to version 3.6.x
Before you upgrade the foundational services installer version, make sure that the installer catalog source image has the correct tag.
If, during installation, you had set the catalog source image tag as latest, you do not need to manually change the tag.
If, during installation, you had set the catalog source image tag to a specific version, you must update the tag with the version that you want to upgrade to. Or, you can change the tag to latest to automatically complete future upgrades to the most current version.
To update the tag, complete the following actions.
To update the catalog source image tag, run the following command.
oc edit catalogsource opencloud-operators -n openshift-marketplace
Update the image tag.
Change image tag to the specific version of 3.6.x. The 3.6.3 tag is used as an example here:
spec:
displayName: IBMCS Operators
image: 'docker.io/ibmcom/ibm-common-service-catalog:3.6.3'
publisher: IBM
sourceType: grpc
updateStrategy:
registryPoll:
interval: 45m
Change the image tag to latest to automatically upgrade to the most current version.
spec:
displayName: IBMCS Operators
image: 'icr.io/cpopen/ibm-common-service-catalog:latest'
publisher: IBM
sourceType: grpc
updateStrategy:
registryPoll:
interval: 45m
To check whether the image tag is successfully updated, run the following command:
oc get catalogsource opencloud-operators -n openshift-marketplace -o jsonpath='{.spec.image}{"\n"}{.status.connectionState.lastObservedState}'
The following sample output has the image tag and its status:
icr.io/cpopen/ibm-common-service-catalog:latest
READY%
An administrator is using the Storage Suite for Cloud Paks entitlement that they received with their Cloud Pak for Integration (CP4I) licenses. The administrator has 200 VPC of CP4I and wants to be licensed to use 8TB of OpenShift Container Storage for 3 years. They have not used or allocated any of their Storage Suite entitlement so far.
What actions must be taken with their Storage Suite entitlement?
The Storage Suite entitlement covers the administrator's license needs only if the OpenShift cluster is running on IBM Cloud or AWS.
The Storage Suite entitlement can be used for OCS. however 8TB will require 320 VPCs of CP41
The Storage Suite entitlement already covers the administrator's license needs.
The Storage Suite entitlement only covers IBM Spectrum Scale, Spectrum Virtualize. Spectrum Discover, and Spectrum Protect Plus products, but the licenses can be converted to OCS.
The IBM Storage Suite for Cloud Paks provides storage licensing for various IBM Cloud Pak solutions, including Cloud Pak for Integration (CP4I). It supports multiple storage options, such as IBM Spectrum Scale, IBM Spectrum Virtualize, IBM Spectrum Discover, IBM Spectrum Protect Plus, and OpenShift Container Storage (OCS).
IBM licenses CP4I based on Virtual Processor Cores (VPCs).
Storage Suite for Cloud Paks uses a conversion factor:
1 VPC of CP4I provides 25GB of OCS storage entitlement.
To calculate how much CP4I VPC is required for 8TB (8000GB) of OCS:
Understanding Licensing Conversion:8000GB25GB per VPC=320 VPCs\frac{8000GB}{25GB \text{ per VPC}} = 320 \text{ VPCs}25GB per VPC8000GB=320 VPCs
Since the administrator only has 200 VPCs of CP4I, they do not have enough entitlement to cover the full 8TB of OCS storage. They would need an additional 120 VPCs to fully meet the requirement.
A. The Storage Suite entitlement covers the administrator's license needs only if the OpenShift cluster is running on IBM Cloud or AWS.
Incorrect, because Storage Suite for Cloud Paks can be used on any OpenShift deployment, including on-premises, IBM Cloud, AWS, or other cloud providers.
C. The Storage Suite entitlement already covers the administrator's license needs.
Incorrect, because 200 VPCs of CP4I only provide 5TB (200 × 25GB) of OCS storage, but the administrator needs 8TB.
D. The Storage Suite entitlement only covers IBM Spectrum products, but the licenses can be converted to OCS.
Incorrect, because Storage Suite already includes OpenShift Container Storage (OCS) as part of its licensing model without requiring any conversion.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Storage Suite for Cloud Paks Licensing Guide
IBM Cloud Pak for Integration Licensing Information
OpenShift Container Storage Entitlement
The following deployment topology has been created for an API Connect deploy-ment by a client.
Which two statements are true about the topology?
A. Regular back-ups of the API Manager and Portal have to be taken and these backups should be replicated
to the second site.
This represents a Active/Passive deployment (or Portal and Management ser-vices.
This represents a distributed Kubernetes cluster across the sites.
In case of Data Center J failing, the Kubernetes service of Data Center 2 will detect and instantiate the portal and management services on Data Center 2.
This represents an Active/Active deployment for Gateway and Analytics services.
IBM API Connect, as part of IBM Cloud Pak for Integration (CP4I), supports various deployment topologies, including Active/Active and Active/Passive configurations across multiple data centers. Let's analyze the provided topology carefully:
Backup Strategy (Option A - Correct)
The API Manager and Developer Portal components are stateful and require regular backups.
Since the topology spans across two sites, these backups should be replicated to the second site to ensure disaster recovery (DR) and high availability (HA).
This aligns with IBM’s best practices for multi-data center deployment of API Connect.
Deployment Mode for API Manager & Portal (Option B - Incorrect)
The question suggests that API Manager and Portal are deployed across two sites.
If it were an Active/Passive deployment, only one site would be actively handling requests, while the second remains idle.
However, in IBM’s recommended architectures, API Manager and Portal are usually deployed in an Active/Active setup with proper failover mechanisms.
Cluster Type (Option C - Incorrect)
A distributed Kubernetes cluster across multiple sites would require an underlying multi-cluster federation or synchronization.
IBM API Connect is usually deployed on separate Kubernetes clusters per data center, rather than a single distributed cluster.
Therefore, this topology does not represent a distributed Kubernetes cluster across sites.
Failover Behavior (Option D - Incorrect)
Kubernetes cannot automatically detect failures in Data Center 1 and migrate services to Data Center 2 unless specifically configured with multi-cluster HA policies and disaster recovery.
Instead, IBM API Connect HA and DR mechanisms would handle failover via manual or automated orchestration, but not via Kubernetes native services.
Gateway and Analytics Deployment (Option E - Correct)
API Gateway and Analytics services are typically deployed in Active/Active mode for high availability and load balancing.
This means that traffic is dynamically routed to the available instance in both sites, ensuring uninterrupted API traffic even if one data center goes down.
Final Answer:✅ A. Regular backups of the API Manager and Portal have to be taken, and these backups should be replicated to the second site.✅ E. This represents an Active/Active deployment for Gateway and Analytics services.
IBM API Connect Deployment Topologies
IBM Documentation – API Connect Deployment Models
High Availability and Disaster Recovery in IBM API Connect
IBM API Connect HA & DR Guide
IBM Cloud Pak for Integration Architecture Guide
IBM Cloud Pak for Integration Docs
References:
What is one method that can be used to uninstall IBM Cloud Pak for Integra-tion?
Uninstall.sh
Cloud Pak for Integration console
Operator Catalog
OpenShift console
Uninstalling IBM Cloud Pak for Integration (CP4I) v2021.2 requires removing the operators, instances, and related resources from the OpenShift cluster. One method to achieve this is through the OpenShift console, which provides a graphical interface for managing operators and deployments.
The OpenShift Web Console allows administrators to:
Navigate to Operators → Installed Operators and remove CP4I-related operators.
Delete all associated custom resources (CRs) and namespaces where CP4I was deployed.
Ensure that all PVCs (Persistent Volume Claims) and secrets associated with CP4I are also deleted.
This is an officially supported method for uninstalling CP4I in OpenShift environments.
Why Option D (OpenShift Console) is Correct:
A. Uninstall.sh → ❌ Incorrect
There is no official Uninstall.sh script provided by IBM for CP4I removal.
IBM’s documentation recommends manual removal through OpenShift.
B. Cloud Pak for Integration console → ❌ Incorrect
The CP4I console is used for managing integration components but does not provide an option to uninstall CP4I itself.
C. Operator Catalog → ❌ Incorrect
The Operator Catalog lists available operators but does not handle uninstallation.
Operators need to be manually removed via the OpenShift Console or CLI.
Explanation of Incorrect Answers:
Uninstalling IBM Cloud Pak for Integration
OpenShift Web Console - Removing Installed Operators
Best Practices for Uninstalling Cloud Pak on OpenShift
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
What type of storage is required by the API Connect Management subsystem?
NFS
RWX block storage
RWO block storage
GlusterFS
In IBM API Connect, which is part of IBM Cloud Pak for Integration (CP4I), the Management subsystem requires block storage with ReadWriteOnce (RWO) access mode.
The API Connect Management subsystem handles API lifecycle management, analytics, and policy enforcement.
It requires high-performance, low-latency storage, which is best provided by block storage.
The RWO (ReadWriteOnce) access mode ensures that each persistent volume (PV) is mounted by only one node at a time, preventing data corruption in a clustered environment.
IBM Cloud Block Storage
AWS EBS (Elastic Block Store)
Azure Managed Disks
VMware vSAN
Why "RWO Block Storage" is Required?Common Block Storage Options for API Connect on OpenShift:
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. NFS
❌ Incorrect – Network File System (NFS) is a shared file storage (RWX) and does not provide the low-latency performance needed for the Management subsystem.
❌
B. RWX block storage
❌ Incorrect – RWX (ReadWriteMany) block storage is not supported because it allows multiple nodes to mount the volume simultaneously, leading to data inconsistency for API Connect.
❌
D. GlusterFS
❌ Incorrect – GlusterFS is a distributed file system, which is not recommended for API Connect’s stateful, performance-sensitive components.
❌
Final Answer:✅ C. RWO block storage
IBM API Connect System Requirements
IBM Cloud Pak for Integration Storage Recommendations
Red Hat OpenShift Storage Documentation
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Which statement describes the Aspera High Speed Transfer Server (HSTS) within IBM Cloud Pak for Integration?
HSTS allows an unlimited number of concurrent users to transfer files of up to 500GB at high speed using an Aspera client.
HSTS allows an unlimited number of concurrent users to transfer files of up to 100GB at high speed using an Aspera client.
HSTS allows an unlimited number of concurrent users to transfer files of up to 1TB at highs peed using an Aspera client.
HSTS allows an unlimited number of concurrent users to transfer files of any size at high speed using an Aspera client.
IBM Aspera High-Speed Transfer Server (HSTS) is a core component of IBM Cloud Pak for Integration (CP4I) that enables secure, high-speed file transfers over networks, regardless of file size, distance, or network conditions.
HSTS does not impose a file size limit, meaning users can transfer files of any size efficiently.
It uses IBM Aspera’s FASP (Fast and Secure Protocol) to achieve transfer speeds significantly faster than traditional TCP-based transfers, even over long distances or unreliable networks.
HSTS allows an unlimited number of concurrent users to transfer files using an Aspera client.
It ensures secure, encrypted, and efficient file transfers with features like bandwidth control and automatic retry in case of network failures.
A. HSTS allows an unlimited number of concurrent users to transfer files of up to 500GB at high speed using an Aspera client. (Incorrect)
Incorrect file size limit – HSTS supports files of any size without restrictions.
B. HSTS allows an unlimited number of concurrent users to transfer files of up to 100GB at high speed using an Aspera client. (Incorrect)
Incorrect file size limit – There is no 100GB limit in HSTS.
C. HSTS allows an unlimited number of concurrent users to transfer files of up to 1TB at high speed using an Aspera client. (Incorrect)
Incorrect file size limit – There is no 1TB limit in HSTS.
D. HSTS allows an unlimited number of concurrent users to transfer files of any size at high speed using an Aspera client. (Correct)
Correct answer – HSTS does not impose a file size limit, making it the best choice.
Analysis of the Options:
IBM Aspera High-Speed Transfer Server Documentation
IBM Cloud Pak for Integration - Aspera Overview
IBM Aspera FASP Technology
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
For manually managed upgrades, what is one way to upgrade the Automation As-sets (formerly known as Asset Repository) CR?
Use the OpenShift web console to edit the YAML definition of the Asset Re-pository operand of the IBM Automation foundation assets operator.
In OpenShift web console, navigate to the OperatorHub and edit the Automa-tion foundation assets definition.
Open the terminal window and run "oc upgrade ..." command,
Use the OpenShift web console to edit the YAML definition of the IBM Auto-mation foundation assets operator.
In IBM Cloud Pak for Integration (CP4I) v2021.2, the Automation Assets (formerly known as Asset Repository) is managed through the IBM Automation Foundation Assets Operator. When manually upgrading Automation Assets, you need to update the Custom Resource (CR) associated with the Asset Repository.
The correct approach to manually upgrading the Automation Assets CR is to:
Navigate to the OpenShift Web Console.
Go to Operators → Installed Operators.
Find and select IBM Automation Foundation Assets Operator.
Locate the Asset Repository operand managed by this operator.
Edit the YAML definition of the Asset Repository CR to reflect the new version or required configuration changes.
Save the changes, which will trigger the update process.
This approach ensures that the Automation Assets component is upgraded correctly without disrupting the overall IBM Cloud Pak for Integration environment.
B. In OpenShift web console, navigate to the OperatorHub and edit the Automation foundation assets definition.
The OperatorHub is used for installing and subscribing to operators but does not provide direct access to modify Custom Resources (CRs) related to operands.
C. Open the terminal window and run "oc upgrade ..." command.
There is no oc upgrade command in OpenShift. Upgrades in OpenShift are typically managed through CR updates or Operator Lifecycle Manager (OLM).
D. Use the OpenShift web console to edit the YAML definition of the IBM Automation foundation assets operator.
Editing the operator’s YAML would affect the operator itself, not the Asset Repository operand, which is what needs to be upgraded.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Cloud Pak for Integration Knowledge Center
IBM Automation Foundation Assets Documentation
OpenShift Operator Lifecycle Manager (OLM) Guide
An account lockout policy can be created when setting up an LDAP server for the Cloud Pak for Integration platform. What is this policy used for?
It warns the administrator if multiple login attempts fail.
It prompts the user to change the password.
It deletes the user account.
It restricts access to the account if multiple login attempts fail.
In IBM Cloud Pak for Integration (CP4I) v2021.2, when integrating LDAP (Lightweight Directory Access Protocol) for authentication, an account lockout policy can be configured to enhance security.
The account lockout policy is designed to prevent brute-force attacks by temporarily or permanently restricting user access after multiple failed login attempts.
If a user enters incorrect credentials multiple times, the account is locked based on the configured policy.
The lockout can be temporary (auto-unlock after a period) or permanent (admin intervention required).
This prevents attackers from guessing passwords through repeated login attempts.
The policy's main function is to restrict access after repeated failed attempts, ensuring security.
It helps mitigate brute-force attacks and unauthorized access.
LDAP enforces the lockout rules based on the organization's security settings.
How the Account Lockout Policy Works:Why Answer D is Correct?
A. It warns the administrator if multiple login attempts fail. → Incorrect
While administrators may receive alerts, the primary function of the lockout policy is to restrict access, not just warn the admin.
B. It prompts the user to change the password. → Incorrect
An account lockout prevents login rather than prompting a password change.
Password change prompts usually happen for expired passwords, not failed logins.
C. It deletes the user account. → Incorrect
Lockout disables access but does not delete the user account.
Explanation of Incorrect Answers:
IBM Cloud Pak for Integration Security & LDAP Configuration
IBM Cloud Pak Foundational Services - Authentication & User Management
IBM Cloud Pak for Integration - Managing User Access
IBM LDAP Account Lockout Policy Guide
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
The OpenShift Logging Elasticsearch instance is optimized and tested for short term storage. Approximately how long will it store data for?
1 day
30 days
7 days
6 months
In IBM Cloud Pak for Integration (CP4I) v2021.2, OpenShift Logging utilizes Elasticsearch as its log storage backend. The default configuration of the OpenShift Logging stack is optimized for short-term storage and is designed to retain logs for approximately 7 days before they are automatically purged.
Performance Optimization: The OpenShift Logging Elasticsearch instance is designed for short-term log retention to balance storage efficiency and performance.
Default Curator Configuration: OpenShift Logging uses Elasticsearch Curator to manage the log retention policy, and by default, it is set to delete logs older than 7 days.
Designed for Operational Logs: The default OpenShift Logging stack is intended for short-term troubleshooting and monitoring, not long-term log archival.
Why is the retention period 7 days?If longer retention is required, organizations can:
Configure a different retention period by modifying the Elasticsearch Curator settings.
Forward logs to an external log storage system like Splunk, IBM Cloud Object Storage, or another long-term logging solution.
A. 1 day – Too short; OpenShift Logging does not delete logs on a daily basis by default.
B. 30 days – The default retention period is 7 days, not 30. A 30-day retention period would require manual configuration changes.
D. 6 months – OpenShift Logging is not optimized for such long-term storage. Long-term log retention should be managed using external storage solutions.
Why Other Options Are Incorrect:IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
IBM Cloud Pak for Integration Logging and Monitoring
Red Hat OpenShift Logging Documentation
Configuring OpenShift Logging Retention Policy
Which statement is true about App Connect Designer?
Only one instance of App Connect Designer can be created in a namespace.
For each App Connect Designer instance, a corresponding toolkit instance must be created.
Multiple instances of App Connect Designer can be created in a namespace.
App Connect Designer must be linked to a toolkit for validation.
In IBM Cloud Pak for Integration (CP4I) v2021.2, App Connect Designer is a low-code integration tool that enables users to design and deploy integrations between applications and services. It runs as a containerized service within OpenShift.
OpenShift supports multi-instance deployments, allowing users to create multiple instances of App Connect Designer within the same namespace.
This flexibility enables organizations to run separate designer instances for different projects, teams, or environments within the same namespace.
Each instance operates independently, and users can configure them with different settings and access controls.
Why Option C is Correct:
Explanation of Incorrect Answers:
What role is required to install OpenShift GitOps?
cluster-operator
cluster-admin
admin
operator
In Red Hat OpenShift, installing OpenShift GitOps (based on ArgoCD) requires elevated cluster-wide permissions because the installation process:
Deploys Custom Resource Definitions (CRDs).
Creates Operators and associated resources.
Modifies cluster-scoped components like role-based access control (RBAC) policies.
Only a user with cluster-admin privileges can perform these actions, making cluster-admin the correct role for installing OpenShift GitOps.
Command to Install OpenShift GitOps:oc apply -f openshift-gitops-subscription.yaml
This operation requires cluster-wide permissions, which only the cluster-admin role provides.
Why the Other Options Are Incorrect?Option
Explanation
Correct?
A. cluster-operator
❌ Incorrect – No such default role exists in OpenShift. Operators are managed within namespaces but cannot install GitOps at the cluster level.
❌
C. admin
❌ Incorrect – The admin role provides namespace-level permissions, but GitOps requires cluster-wide access to install Operators and CRDs.
❌
D. operator
❌ Incorrect – This is not a valid OpenShift role. Operators are software components managed by OpenShift, but an operator role does not exist for installation purposes.
❌
Final Answer:✅ B. cluster-admin
Red Hat OpenShift GitOps Installation Guide
Red Hat OpenShift RBAC Roles and Permissions
IBM Cloud Pak for Integration - OpenShift GitOps Best Practices
IBM Cloud Pak for Integration (CP4I) v2021.2 Administration References:
Copyright © 2014-2025 Examstrust. All Rights Reserved