A system was developed for screening the X-rays of patients for potential malignancy detection (skin cancer). A workflow system has been developed to screen multiple cancers by using several individually trained ML models chained together in the workflow.
Testing the pipeline could involve multiple kind of tests (I - III):
I.Pairwise testing of combinations
II.Testing each individual model for accuracy
III.A/B testing of different sequences of models
Which ONE of the following options contains the kinds of tests that would be MOST APPROPRIATE to include in the strategy for optimal detection?
SELECT ONE OPTION
A motorcycle engine repair shop owner wants to detect a leaking exhaust valve and fix it before it falls and causes catastrophic damage to the engine. The shop developed and trained a predictive model with historical data files from known health engines and ones which experienced a catastrophic fails due to exhaust valve failure. The shop evaluated 200 engines using this model and then disassembled the engines to assess the true state of the valves, recording the results in the confusion matrix below.
What is the precision of this predictive model
A bank wants to use an algorithm to determine which applicants should be given a loan. The bank hires a data scientist to construct a logistic regression model to predict whether the applicant will repay the loan or not. The bank has enough data on past customers to randomly split the data into a training data set and a test/validation data set. A logistic regression model is constructed on the training data set using the following independent variables:
Gender
Marital status
Number of dependents
Education
Income
Loan amount
Loan term
Credit score
The model reveals that those with higher credit scores and larger total incomes are more likely to repay their loans. The data scientist has suggested that there might be bias present in the model based on previous models created for other banks.
Given this information, what is the best test approach to check for potential bias in the model?
A tourist calls an airline to book a ticket and is connected with an automated system which is able to recognize speech, understand requests related to purchasing a ticket, and provide relevant travel options. When the tourist asks about the expected weather at the destination or potential impacts on operations because of the tight labor market the only response from the automated system is: "Idon't understand your question."
This AI system should be categorized as?
A mobile app start-up company is implementing an AI-based chat assistant for e-commerce customers. In the process of planning the testing, the team realizes that the specifications are insufficient.
Which testing approach should be used to test this system?
Max. Score: 2
Al-enabled medical devices are used nowadays for automating certain parts of the medical diagnostic processes. Since these are life-critical process the relevant authorities are considenng bringing about suitable certifications for these Al enabled medical devices. This certification may involve several facets of Al testing (I - V).
I.Autonomy
II.Maintainability
III.Safety
IV.Transparency
V.Side Effects
Which ONE of the following options contains the three MOST required aspects to be satisfied for the above scenario of certification of Al enabled medical devices?
SELECT ONE OPTION
You are testing an autonomous vehicle which uses AI to determine proper driving actions and responses. You have evaluated the parameters and combinations to be tested and have determinedthat there are too many to test in the time allowed. It has been suggested that you use pairwise testing to limit the parameters. Given the complexity of the software under test, what is likely the outcome from using pairwise testing?
Which ONE of the following characteristics is the least likely to cause safety related issues for an Al system?
SELECT ONE OPTION
Which of the following problems would best be solved using the supervised learning category of regression?
Which ONE of the following options is an example that BEST describes a system with Al-based autonomous functions?
SELECT ONE OPTION
A transportation company operates three types of delivery vehicles in its fleet. The vehicles operate at different speeds (slow, medium, and fast). The transportation company is attempting to optimize scheduling and has created an AI-based program to plan routes for its vehicles using records from the medium-speed vehicle traveling to selected destinations. The test team uses this data in metamorphic testing to test the accuracy of the estimated travel times created by the AI route planner with the actual routes and times.
Which of the following describes the next phase of metamorphic testing?
A company is using a spam filter to attempt to identify which emails should be marked as spam. Detection rules are created by the filter that causes a message to be classified as spam. An attacker wishes to have all messages internal to the company be classified as spam. So, the attacker sends messages with obvious red flags in the body of the email and modifies the from portion of the email to make it appear that the emails have been sent by company members. The testers plan to use exploratory data analysis (EDA) to detect the attack and use this information to prevent future adversarial attacks.
How could EDA be used to detect this attack?
“BioSearch” is creating an Al model used for predicting cancer occurrence via examining X-Ray images. The accuracy of the model in isolation has been found to be good. However, the users of the model started complaining of the poor quality of results, especially inability to detect real cancer cases, when put to practice in the diagnosis lab, leading to stopping of the usage of the model.
A testing expert was called in to find the deficiencies in the test planning which led to the above scenario.
Which ONE of the following options would you expect to MOST likely be the reason to be discovered by the test expert?
SELECT ONE OPTION
A ML engineer is trying to determine the correctness of the new open-source implementation *X", of a supervised regression algorithm implementation. R-Square is one of the functional performance metrics used to determine the quality of the model.
Which ONE of the following would be an APPROPRIATE strategy to achieve this goal?
SELECT ONE OPTION
Which ONE of the following combinations of Training, Validation, Testing data is used during the process of learning/creating the model?
SELECT ONE OPTION
The stakeholders of a machine learning model have confirmed that they understand the objective and purpose of the model, and ensured that the proposed model aligns with their business priorities. They have also selected a framework and a machine learning model that they will be using.
What should be the next step to progress along the machine learning workflow?
Consider a natural language processing (NLP) algorithm that attempts to predict the next word that you would like to type in a text message. An update to the algorithm has been created that should increase the accuracy of the predictions based on user typing patterns. The old algorithm was rated for accuracy by the users. Then, after the new update was released, the users rated the updated algorithm. A statistical test was used to compare between the two versions of the algorithm to see whether or not the update should remain in place.
This is an example of what type of testing?
Which ONE of the following options describes the LEAST LIKELY usage of Al for detection of GUI changes due to changes in test objects?
SELECT ONE OPTION
Data used for an object detection ML system was found to have been labelled incorrectly in many cases.
Which ONE of the following options is most likely the reason for this problem?
SELECT ONE OPTION
Which of the following is correct regarding the layers of a deep neural network?
"AllerEgo" is a product that uses sell-learning to predict the behavior of a pilot under combat situation for a variety of terrains and enemy aircraft formations. Post training the model was exposed to the real-
world data and the model was found to be behaving poorly. A lot of data quality tests had been performed on the data to bring it into a shape fit for training and testing.
Which ONE of the following options is least likely to describes the possible reason for the fall in the performance, especially when considering the self-learning nature of the Al system?
SELECT ONE OPTION
The difficulty of defining criteria for improvement before the model can be accepted.
The fast pace of change did not allow sufficient time for testing.
The unknown nature and insufficient specification of the operating environment might have caused the poor performance.
Upon testing a model used to detect rotten tomatoes, the following data was observed by the test engineer, based on certain number of tomato images.
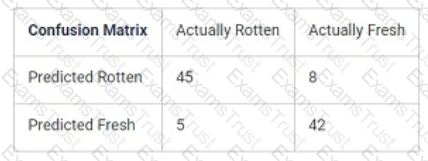
For this confusion matrix which combinations of values of accuracy, recall, and specificity respectively is CORRECT?
SELECT ONE OPTION
In a certain coffee producing region of Colombia, there have been some severe weather storms, resulting in massive losses in production. This caused a massive drop in stock price of coffee.
Which ONE of the following types of testing SHOULD be performed for a machine learning model for stock-price prediction to detect influence of such phenomenon as above on price of coffee stock.
SELECT ONE OPTION
There is a growing backlog of unresolved defects for your project. You know the developers have an ML model that they have created which has learned which developers work on which type of software and the speed with which they resolve issues. How could you use this model to help reduce the backlog and implement more efficient defect resolution?