Examine this data in the EMPLOYERS table:

Which statement will execute successfully?
SELECT dept_id, MAX (Last_name), SUM (salary) FROM employees GROUP BY dept_id
SELECT dept_id, LENGTH (last_name), SUM (salary) FROM employees GROUP BY dept_id
SELECT dept_id, STDDEV (last_name), SUM (salary) FROM employees GROUP BY dept_id
SELECT dept_id, INSTR (last_name,'A'), SUM (salary) FROM employees GROUP BY dept_id
In SQL, the GROUP BY clause is used in conjunction with aggregate functions to group the result-set by one or more columns.
A. This statement will execute successfully. MAX() is an aggregate function that can be used to return the highest value of the selected column, and SUM() is an aggregate function used to sum the values. Both are valid in the SELECT statement with a GROUP BY clause grouping the results by dept_id.
B. This statement will not execute successfully when used with GROUP BY because LENGTH(last_name) is not an aggregate function and it doesn't appear in the GROUP BY clause. All selected columns that are not under an aggregate function must be included in the GROUP BY clause.
C. This statement will not execute successfully because STDDEV() is an aggregate function that calculates the standard deviation of a set of numbers, and it can only be used on numeric data types. last_name is not a numeric column.
D. This statement will not execute successfully for the same reason as B: INSTR(last_name, 'A') is not an aggregate function and must appear in the GROUP BY clause if it's in the SELECT clause.
The SYSDATE function displays the current Oracle Server date as:
21 -MAY-19
You wish to display the date as:
MONDAY, 21 MAY, 201 9
Which statement will do this?
SELECT TO _ CHAR (SYSDATE, ' FMDAY, DD MONTH, YYYY') FROM DUAL;
SELECT TO _ DATE (SYSDATE, ' FMDAY, DD MONTH, YYYY') FROM DUAL;
SELECT TO_ CHAR (SYSDATE, ' FMDD, DAY MONTH, YYYY') FROM DUAL;
SELECT TO_ CHAR (SYSDATE, ' FMDAY, DDTH MONTH, YYYY') FROM DUAL;
To format a date in Oracle SQL, TO_CHAR function is used to convert date types to string with a specified format:
Option A: SELECT TO_CHAR(SYSDATE, 'FMDAY, DD MONTH, YYYY') FROM DUAL;
This correctly applies the date format model 'FMDAY, DD MONTH, YYYY', which will display the date as requested: "MONDAY, 21 MAY, 2019". FM modifier is used to remove padding blanks or leading zeros.
Options B, C, and D do not achieve the desired output:
Option B is incorrect because TO_DATE converts a string to a date, not format a date.
Option C and D have incorrect format strings that do not match the required output format.
In the PROMOTIONS table, the PROMO_BEGTN_DATE column is of data type DATE and the default date format is DD-MON-RR.
Which two statements are true about expressions using PROMO_BEGIN_DATE contained in a query?
TO_NUMBER(PROMO_BEGIN_DATE)-5 will return number
TO_DATE(PROMO_BEGIN_DATE * 5) will return a date
PROMO_BEGIN_DATE-SYSDATE will return a number.
PROMO_BEGIN_DATE-5 will return a date.
PROMO_BEGIN_DATE-SYSDATE will return an error.
A. This statement is incorrect because TO_NUMBER expects a character string as an argument, not a date. Directly converting a date to a number without an intermediate conversion to a character string would result in an error. B. This statement is incorrect. Multiplying a date by a number does not make sense in SQL, and attempting to convert such an expression to a date will also result in an error. C. This statement is correct. Subtracting two dates in Oracle SQL results in the number of days between those dates, hence the result is a number. D. This statement is correct. Subtracting a number from a date in Oracle SQL will subtract that number of days from the date, returning another date. E. This statement is incorrect. As stated in C, subtracting a date from SYSDATE correctly returns the number of days between those two dates, not an error.
These concepts are explained in the Oracle Database SQL Language Reference, which details date arithmetic in SQL.
Which two join conditions in a from clause are non-equijoins?
tablet join table2 ON (table1.column = table2.column) where table2.column LIKE 'A'
table1 join table2 on (table1.column between table2.column] and table2.column2)
table1 natural JOIN table2
table1 join table2 using (column1, column2)
table1 join table2 ON (table1.column >= table2.column)
Equijoins are joins that use the equality operator (=) to match rows. Non-equijoins are joins that use operators other than the equality operator.
A. False. This condition is an equijoin as it uses the equality operator (=).
B. True. This join condition uses the BETWEEN operator, which is not based on equality.
C. False. A natural join is a type of equijoin where the join is made on all columns with the same names in both tables.
D. False. USING clause is used to specify an equijoin on one or more columns.
E. True. This join condition uses the greater than or equal to (>=) operator, making it a non-equijoin.
Which three statements are true about a self join?
It must be an inner join.
It can be an outer join.
The ON clause must be used.
It must be an equijoin.
The query must use two different aliases for the table.
The ON clause can be used.
A self-join is used to join a table to itself, and here's why the selected answers are correct:
Option B: It can be an outer join.A self-join can indeed be either an inner or an outer join, allowing for more flexibility in how records are matched and returned, especially useful in hierarchical or sequential data scenarios.
Option E: The query must use two different aliases for the table.When performing a self-join, aliases are necessary to distinguish between the different instances of the same table in the query.
Option F: The ON clause can be used.In SQL, the ON clause specifies the conditions that match rows in a self-join, offering a clear and structured way to define how the join works.
Other options are not universally true:
Option A: It must be an inner join. Incorrect because, as explained, outer joins are also possible.
Option C: The ON clause must be used. Incorrect because the WHERE clause might also be used to specify the join condition.
Option D: It must be an equijoin. Incorrect because non-equijoins (like non-equality comparisons) can also be used in self-joins.
Which three actions can you perform by using the ORACLE DATAPUMP access driver?
Create a directory object for an external table.
Read data from an external table and load it into a table in the database.
Query data from an external table.
Create a directory object for a flat file.
Execute DML statements on an external table.
Read data from a table in the database and insert it into an external table.
The Oracle Data Pump access driver allows for specific actions with external tables:
B. Read data from an external table and load it into a table in the database. Data Pump can be used to efficiently transfer data between external tables and internal database tables.
C. Query data from an external table. The Data Pump access driver supports querying data directly from external tables.
F. Read data from a table in the database and insert it into an external table. The Data Pump can also export data from database tables to external table formats.
Options A, D, and E are incorrect:
A and D are incorrect as the creation of a directory object is not specific to the Data Pump access driver but is a general external table requirement.
E is incorrect because DML operations directly on external tables are not supported; they are read-only.
View the Exhibit and examine the structure of the ORDERS table.
The columns ORDER_MODE and ORDER TOTAL have the default values'direct “and respectively.
Which two INSERT statements are valid? (Choose two.)
INSERT INTO (SELECT order_id, order date, customer_id FROM orders) VALUES (1, ‘09-mar-2007“,101);
INSERT INTO orders (order_id, order_date, order mode,customer_id, order_total) VALUES (1, TO_DATE (NULL),‘online‘,101, NULL) ;
INSERT INTO orders VALUES (1, ‘09-mar-2007’, ‘online’,’ ’,1000);
INSERT INTO orders (order id, order_date, order mode, order_total)VALUES (1,‘10-mar-2007’,’online’, 1000)
INSERT INTO orders VALUES(‘09-mar-2007’,DEFAULT,101, DEFALLT);
Regarding valid INSERT statements into the ORDERS table:
B. This is a valid statement because it uses TO_DATE for potentially setting a NULL date and provides defaults implicitly where not specified, adhering to the column constraints and requirements.
D. This statement is correctly formatted and provides values for non-optional fields, using DEFAULT implicitly for unspecified optional fields.
Incorrect options:
A: The subquery format and values provided do not match the expected column count and types for direct insert.
C: Incorrect format due to an improper string for the ORDER_MODE and possibly incomplete values.
E: Incorrect syntax; DEFAULT should be correctly capitalized, and the value order and type must match the table structure.
You have been asked to create a table for a banking application.
One of the columns must meet three requirements:
1: Be stored in a format supporting date arithmetic without using conversion functions
2: Store a loan period of up to 10 years
3: Be used for calculating interest for the number of days the loan remains unpaid Which data type should you use?
TIMESTAMP WITH TIMEZONE
TIMESTAMP
TIMESTAMP WITH LOCAL TIMEZONE
INTERVAL YEAR TO MONTH
INTERVAL DAY TO SECOND
The requirements specify that the data type must support date arithmetic, store a specific period (up to 10 years in terms of days), and be used for day-level calculations. The appropriate data type is:
A: Incorrect. TIMESTAMP WITH TIMEZONE stores date and time with time zone information, which is not specifically needed for arithmetic or interval storage.
B: Incorrect. TIMESTAMP stores date and time without considering time zone or providing interval arithmetic functionality.
C: Incorrect. TIMESTAMP WITH LOCAL TIMEZONE adjusts the time zone but does not inherently support interval arithmetic or storage.
D: Incorrect. INTERVAL YEAR TO MONTH is used for storing periods in terms of years and months, not suitable for daily calculations.
E: Correct. INTERVAL DAY TO SECOND allows storage of periods in terms of days, hours, minutes, and seconds, meeting all the given requirements for precision and functionality in date arithmetic related to daily calculations.
Examine this Statement which returns the name of each employee and their manager,
SELECT e.last name AS emp,,m.last_name AS mgr
FROM employees e JOIN managers m
ON e.manager_ id = m. employee_ id ORDER BY emp;
You want to extend the query to include employees with no manager. What must you add before JOIN to do this?
CROSS
FULL OUTER
LEFT OUTER
RIGHT OUTER
To include employees with no manager in the query results, a LEFT OUTER JOIN should be used. This type of join returns all records from the left table (employees), and the matched records from the right table (managers). The result is NULL from the right side if there is no match.
Here's the modified query:
SELECT e.last_name AS emp, m.last_name AS mgr FROM employees e LEFT OUTER JOIN managers m ON e.manager_id = m.employee_id ORDER BY emp;
This ensures that even if an employee does not have a manager (i.e., e.manager_id is NULL or there is no corresponding m.employee_id), that employee will still be included in the results.
Which two statements are true about * _TABLES views?
You must have ANY TABLE system privileges, or be granted object privilges on the table, to viewa tabl e in DBA TABLES.
USER TABLES displays all tables owned by the current user.
You must have ANY TABLE system privileges, or be granted object privileges on the table, to view a table in USER_TABLES.
ALL TABLES displays all tables owned by the current user.
You must have ANY TABLE system privileges, or be granted object privileges on the table, to view a table in ALL_TABLES.
All users can query DBA_TABLES successfully.
In Oracle, *_TABLES views provide information about tables.
B. USER_TABLES displays all tables owned by the current user, making this statement true. No additional privileges are required to see your own tables.
D. ALL_TABLES displays all tables that the current user has access to, either through direct ownership or through privileges, making this statement true.
A, C, E, and F are incorrect. Specifically:
A and E are incorrect because you do not need ANY TABLE system privileges to view tables in DBA_TABLES or ALL_TABLES; you need the SELECT_CATALOG_ROLE or equivalent privileges.
C is incorrect because as a user, you do not need additional privileges to see your own tables in USER_TABLES.
F is incorrect because not all users can query DBA_TABLES; this requires specific privileges or roles.
References:
Oracle Database Reference, 12c Release 1 (12.1): "Static Data Dictionary Views"
Examine the description of the EMPLOYEES table:

NLS_DATE_FORMAT is set to DD-MON-YY.
Which query requires explicit data type conversion?
SELECT salary + 120.50 FROM employees;
SELECT SUBSTR(join date, 1, 2)- 10 FROM employees;
SELECT join date 11.’11 salary FROM employees;
SELECT join date FROM employees where join date > *10-02-2018*;
SELECT join date + 20 FROM employees;
For the EMPLOYEES table and given that NLS_DATE_FORMAT is set to DD-MON-YY, the query that requires explicit data type conversion is:
D. SELECT join_date FROM employees where join_date > '10-02-2018'; This query compares the JOIN_DATE column of type DATE with a string '10-02-2018'. The string must be explicitly converted to a DATE using the TO_DATE function with a format mask that matches the NLS_DATE_FORMAT or the string literal.
Options A, B, C, and E do not necessarily require explicit data type conversion:
A does not require conversion because adding a number to a number column is a valid operation.
B is syntactically incorrect; the correct function to extract a substring is SUBSTR(join_date, 1, 2) and that would require an explicit conversion since JOIN_DATE is a DATE and SUBSTR expects a string, but it seems to be a typo.
C uses an invalid concatenation operation with the pipe symbols, which could be a typo or misunderstanding, but would not typically require a data type conversion.
E requires implicit data type conversion because adding a number to a date is valid in Oracle, which adds the number as days to the date.
Examine the description of the PRODUCTS table:

Which three queries use valid expressions?
SELECT produet_id, unit_pricer, 5 "Discount",unit_price+surcharge-discount FROM products;
SELECT product_id, (unit_price * 0.15 / (4.75 + 552.25)) FROM products;
SELECT ptoduct_id, (expiry_date-delivery_date) * 2 FROM products;
SPLECT product_id, expiry_date * 2 FROM products;
SELEGT product_id, unit_price, unit_price + surcharge FROM products;
SELECT product_id,unit_price || "Discount", unit_price + surcharge-discount FROM products;
B. SELECT product_id, (unit_price * 0.15 / (4.75 + 552.25)) FROM products; C. SELECT product_id, (expiry_date - delivery_date) * 2 FROM products; E. SELECT product_id, unit_price, unit_price + surcharge FROM products;
Comprehensive and Detailed Explanation WITH all References:
A. This is invalid because "Discount" is a string literal and cannot be used without quotes in an arithmetic operation. Also, there is a typo in unit_pricer, and 'discount' is not a defined column in the table. B. This is valid. It shows a mathematical calculation with unit_price, which is of NUMBER type. Division and multiplication are valid operations on numbers. C. This is valid. The difference between two DATE values results in the number of days between them, and multiplying this value by a number is a valid operation. D. This is invalid because expiry_date is of DATE type and cannot be multiplied by a number. Also, there's a typo: "SPLECT" should be "SELECT". E. This is valid. Both unit_price and surcharge are NUMBER types, and adding them together is a valid operation. F. This is invalid because concatenation operator || is used between a number (unit_price) and a string literal "Discount", which is not enclosed in single quotes, and 'discount' is not a defined column in the table.
In SQL, arithmetic operations on numbers and date arithmetic are valid expressions. Concatenation is also a valid expression when used correctly between string values or literals. Operations that involve date types should not include multiplication or division by numbers directly without a proper interval type in Oracle SQL.
These rules are detailed in the Oracle Database SQL Language Reference, where expressions, datatype precedence, and operations are defined.
Examine the ORDER _ITEms table:

Which two queries return rows where QUANTITY is a multiple of ten?
SELECT * FROM order_ items WHERE quantity = TRUNC (quantity, -1);
SELECT * FROM order_ items WHERE MOD (quantity, 10) = 0;
SELECT” FROM order_ items WHERE FLOOR (quantity / 10) = TRUNC (quantity / 10);
SELECT FROM order_ items WHERE quantity / 10 = TRUNC (quantity);
SELECT” FROM order_ _items WHERE quantity = ROUND (quantity, 1);
A: This statement will not work because TRUNC(quantity, -1) will truncate the quantity to zero decimal places when the number is a negative power of ten, which does not guarantee that the quantity is a multiple of ten.
B: This statement is correct. The MOD function returns the remainder of a division. If MOD(quantity, 10) equals zero, it means that quantity is a multiple of ten.
C: This statement is correct. FLOOR(quantity / 10) equals TRUNC(quantity / 10) when quantity is an exact multiple of ten, as FLOOR returns the largest integer less than or equal to a number, and TRUNC will truncate the decimal part.
D: This statement is incorrect because TRUNC(quantity) would remove any decimal places from quantity, and comparing it to quantity / 10 will not guarantee that the quantity is a multiple of ten.
E: This statement is incorrect. ROUND(quantity, 1) will round the quantity to one decimal place, not check if it's a multiple of ten.
You and your colleague Andrew have these privileges on the EMPLOYEE_RECORDS table:
1. SELECT
2. INSERT
3. UPDATE
4. DELETE
You connect to the database instance an perform an update to some of the rows in
EMPLOYEE_RECORDS, but don’t commit yet.
Andrew connects to the database instance and queries the table
No othet user are accessing the table
Which two statements ate true at this point?
Andrew will be able to modify any rows in the table that have not been modified by your transaction
Andrew will be unable to see the changes you have made
Andrew will be able to see the changes you habe made
Andrew will be unable to perform any INSERT, UPDATE of DELETE on the teble
Andrew will be able to SELECT from the table, but be unable to modify any existing rows.
In Oracle Database, when a transaction is not committed, the changes it makes are not visible to other sessions. This is due to Oracle's read consistency model, which means that Andrew will not be able to see the changes you have made until they are committed.
Option A is correct because, in Oracle, another session can modify rows that have not been locked by an uncommitted transaction.
Option C is incorrect because, as per Oracle's read consistency, the changes made by an uncommitted transaction are not visible to other users.
Option D is incorrect because Andrew can perform INSERT, UPDATE, or DELETE operations on the rows that you have not modified.
Option E is incorrect because, while Andrew will be able to SELECT from the table, he will still be able to modify rows that are not locked by your uncommitted update.
References:
Oracle Documentation on Transactions: Transactions
Oracle Documentation on Read Consistency: Read Consistency
Examine this SQL statement:

Which two are true?
The subquery is executed before the UPDATE statement is executed.
All existing rows in the ORDERS table are updated.
The subquery is executed for every updated row in the ORDERS table.
The UPDATE statement executes successfully even if the subquery selects multiple rows.
The subquery is not a correlated subquery.
The provided SQL statement is an update statement that involves a subquery which is correlated to the main query.
A. The subquery is executed before the UPDATE statement is executed. (Incorrect)
This statement is not accurate in the context of correlated subqueries. A correlated subquery is one where the subquery depends on values from the outer query. In this case, the subquery is executed once for each row that is potentially updated by the outer UPDATE statement because it references a column from the outer query (o.customer_id).
B. All existing rows in the ORDERS table are updated. (Incorrect)
Without a WHERE clause in the outer UPDATE statement, this would typically be true. However, the correctness of this statement depends on the actual data and presence of matching customer_id values in both tables. If there are rows in the ORDERS table with customer_id values that do not exist in the CUSTOMERS table, those rows will not be updated.
C. The subquery is executed for every updated row in the ORDERS table. (Correct)
Because the subquery is correlated (references o.customer_id from the outer query), it must be executed for each row to be updated in the ORDERS table to get the corresponding cust_last_name from the CUSTOMERS table.
Which two statements cause changes to the data dictionary?
DELETE FROM scott. emp;
GRANT UPDATE ON scott. emp TO fin manager;
AITER SESSION set NLs. _DATE FORMAT = 'DD/MM/YYYY';
TRUNCATE TABLE emp:
SELECT * FROM user_ tab._ privs;
The data dictionary is a read-only set of tables that provides information about the database. Certain operations that modify the database structure will cause changes to the data dictionary:
Option B: GRANT UPDATE ON scott.emp TO fin_manager;
Granting privileges on a table will change the data dictionary as it records the new privilege.
Option D: TRUNCATE TABLE emp;
Truncating a table affects the data dictionary because it removes all rows from a table and may also reset storage parameters.
Options A, C, and E do not cause changes to the data dictionary:
Option A is incorrect because the DELETE command modifies data, not the data dictionary structure.
Option C is incorrect because altering a session parameter does not change the data dictionary; it is a temporary change for the session.
Option E is incorrect because a SELECT query does not change the database, it just retrieves information.
Table ORDER_ITEMS contains columns ORDER_ID, UNIT_PRICE and QUANTITY, of data type NUMBER
Statement 1:
SELECT MAX (unit price*quantity) "Maximum Order FROM order items;
Statement 2:
SELECT MAX (unit price*quantity "Maximum order" FROM order items GROUP BY order id;
Which two statements are true?
Statement 2 returns only one row of output.
Both the statement given the same output.
Both statements will return NULL if either UNIT PRICE or QUANTITY contains NULL,
Statement 2 may return multiple rows of output.
Statement 1 returns only one row of output.
Analyzing the given SQL statements on the ORDER_ITEMS table:
D. Statement 2 may return multiple rows of output: Statement 2 groups the results by ORDER_ID, which means it calculates the maximum UNIT_PRICE * QUANTITY for each ORDER_ID, potentially returning multiple rows depending on the number of unique ORDER_IDs in the table.
E. Statement 1 returns only one row of output: Statement 1 computes the maximum product of UNIT_PRICE and QUANTITY across all entries in the ORDER_ITEMS table, returning a single row with the maximum value.
Incorrect options:
A: Since Statement 2 groups by ORDER_ID, it does not necessarily return just one row; it returns one row per ORDER_ID.
B: These statements do not yield the same output; Statement 1 returns a single maximum value, while Statement 2 returns the maximum value per ORDER_ID.
C: If either UNIT_PRICE or QUANTITY is NULL, the product for that row will be NULL, but the MAX function ignores NULL values in its calculation unless all rows are NULL, in which case it returns NULL.
Examine this list of requirements for a sequence:
1. Name:EMP_SEQ
2. First value returned:1
3. Duplicates are never permitted.
4. Provide values to be inserted into the EMPLOYEES.EMPLOYEE_ID COLUMN.
5. Reduce the chances of gaps in the values.
Which two statements will satisfy these requirements?
CREATE SEQUENCE emp_seq START WITH 1 INCRENENT BY 1 NOCACHE;
CREATE SEQUENCE emp_seq START WITH 1 INCREMENT BY 1 CYCLE;
CREATE SEQUENCE emp_seq NOCACHE;
CREATE SEQUENCE emp_seq START WITH 1 CACHE;
CREATE SEQUENCE emp_seq START WITH 1 INCREMENT BY 1 CACHE;
CREATE SEQUENCE emp_seq;
A: 'CREATE SEQUENCE emp_seq START WITH 1 INCREMENT BY 1 NOCACHE;' is correct for ensuring unique values without gaps as much as possible by not caching sequence numbers, which might otherwise be lost in a system crash.
B: CYCLE allows the sequence to restart when its max/min value is reached, which does not help with requirement 3 (duplicates are never permitted). Therefore, B is incorrect.
C: This lacks the necessary attributes like START WITH and INCREMENT BY which are crucial to defining a sequence. Thus, statement C is incorrect.
D: 'CREATE SEQUENCE emp_seq START WITH 1 CACHE;' might introduce gaps due to the caching of sequence numbers. This statement is somewhat contrary to requirement 5.
E: 'CREATE SEQUENCE emp_seq START WITH 1 INCREMENT BY 1 CACHE;' will provide continuous unique values, but may include gaps when the cache is lost due to a restart, yet it is more efficient and still generally aligns with the requirements. Hence, statement E is considered correct.
F: This lacks detail and is too ambiguous, lacking the necessary parameters. Therefore, F is incorrect.
Examine this SQL statement:
DELETE FROM employees e
WHERE EXISTS
(SELECT'dummy'
FROM emp_history
WHERE employee_id = e.employee_id)
Which two are true?
The subquery is executed for every row in the EMPLOYEES table.
The subquery is not a correlated subquery.
The subquery is executed before the DELETE statement is executed.
All existing rows in the EMPLOYEE table are deleted.
The DELETE statement executes successfully even if the subquery selects multiple rows.
The provided DELETE statement uses a correlated subquery to determine which rows should be deleted from the EMPLOYEES table.
A. The subquery is indeed executed for every row in the EMPLOYEES table. This is because it references e.employee_id, which is a column from the outer query, making it a correlated subquery.
B. The subquery is a correlated subquery, as explained above.
C. The subquery is executed for each row, not before the DELETE statement.
D. Not all existing rows in the EMPLOYEES table are deleted, only those that have a corresponding employee_id in the EMP_HISTORY table.
E. The DELETE statement executes successfully even if the subquery selects multiple rows because the EXISTS condition only checks for the presence of rows, not their count.
References:
Oracle Database SQL Language Reference 12c Release 1 (12.1), DELETE Statement
Oracle Database SQL Language Reference 12c Release 1 (12.1), Subquery Factoring
Oracle Database SQL Language Reference 12c Release 1 (12.1), Correlated Subqueries
Which two statements will do an implicit conversion?
SELECT * FROM customers WHERE customer_ id = 0001 ;
SELECT * FROM customers WHERE customer id = ‘0001’;
SELECT * FROM customers WHERE insert_ date = DATE ‘2019-01-01’;
SELECT * FROM customers WHERE insert date =’01-JAN-19’
SELECT * FROM customers WHERE TO_ CHAR (customer_ id) =’0001’;
A. True. This statement will work if customer_id is a character data type in the database. Oracle will implicitly convert the numeric literal 0001 to a string to compare with customer_id.
D. True. If the insert_date is of type DATE and the NLS_DATE_FORMAT matches 'DD-MON-YY', Oracle will implicitly convert the string literal '01-JAN-19' to a date type to compare with insert_date.
B is incorrect because if customer_id is a numeric data type, there is no need for implicit conversion. C is incorrect because using the DATE literal DATE '2019-01-01' is an explicit conversion. E is incorrect because TO_CHAR(customer_id) is an explicit conversion from a numeric to a string data type.
You create a table named 123.
Which statement runs successfully?
SELECT * FROM TABLE (123) ;
SELECT * FROM '123';
SELECT * FROM "123";
SELECT * FROM V'123V';
C. True. If you have a table named 123, which is not a standard naming convention because it begins with a digit, you can reference it in SQL by using double quotation marks. The correct syntax to reference a table with a name that does not follow standard naming conventions is to enclose the name in double quotation marks.
A, B, and D are incorrect because they do not use the proper quoting mechanism for a table named with non-standard characters. In Oracle, double quotation marks are used for case-sensitive table names or those that do not follow the usual naming rules.
Which two tasks require subqueries?
Display the total number of products supplied by supplier 102 which have a product status of obsolete.
Display suppliers whose PROD_LIST_PRICE is less than 1000.
Display the number of products whose PROD_LIST_PRICE is more than the average PROD_LIST_PRICE.
Display the minimum PROD_LIST_PRICE for each product status.
Display products whose PROD_MIN_PRICE is more than the average PROD_LIST_PRICE of all products, and whose status is orderable.
C: True. To display the number of products whose PROD_LIST_PRICE is more than the average PROD_LIST_PRICE, you would need to use a subquery to first calculate the average PROD_LIST_PRICE and then use that result to compare each product’s list price to the average.
E: True. Displaying products whose PROD_MIN_PRICE is more than the average PROD_LIST_PRICE of all products and whose status is orderable would require a subquery. The subquery would be used to determine the average PROD_LIST_PRICE, and then this average would be used in the outer query to filter the products accordingly.
Subqueries are necessary when the computation of a value relies on an aggregate or a result that must be obtained separately from the main query, and cannot be derived in a single level of query execution.
References:Oracle's SQL documentation provides guidelines for using subqueries in scenarios where an inner query's result is needed to complete the processing of an outer query.
Which three statements are true about performing DML operations on a view with no Instead of triggers defined?
WITH CHECK clause has no effect when deleting rows from the underlying table through the view.
Insert statements can always be done on a table through a view.
Views cannot be used to add rows to an underlying table if the table has columns with NOT NULL constraints lacking default values which are not referenced in the defining query of the view.
Views cannot be used to add or modify rows in an underlying table if the defining query of the view contains the DISTINCT keyword.
Delete statements can always be done on a table tough a view.
Views cannot be used to query rows from an underlying table if the table has a PRIMARY KEY and the PRIMARY KEY columns are not referenced in the defining query of the view.
When performing DML operations on a view without INSTEAD OF triggers:
Option C: Views cannot be used to add rows to an underlying table if the table has columns with NOT NULL constraints lacking default values which are not referenced in the defining query of the view.
This is true because the view would not provide values for NOT NULL columns without defaults, leading to an error.
Option D: Views cannot be used to add or modify rows in an underlying table if the defining query of the view contains the DISTINCT keyword.
Using DISTINCT in the view’s defining query can make the view non-updatable, as it may aggregate multiple rows into one.
Option E: Delete statements can always be done on a table through a view.
Deletes through a view are typically unrestricted as long as the view does not involve aggregates, DISTINCT, or similar constructs that would logically preclude determining which underlying rows should be deleted.
Which two statements are true about truncate and delete?
the result of a delete can be undone by issuing a rollback
delete can use a where clause to determine which row(s) should be removed.
TRUNCATE can use a where clause to determine which row(s) should be removed.
truncate leavers any indexes on the table in an UNUSABLE STATE.
the result of a truncate can be undone by issuing a ROLLBACK.
In the case of SQL commands TRUNCATE and DELETE:
A. the result of a delete can be undone by issuing a rollback: DELETE is a DML operation that affects rows individually and can be rolled back if it is performed within a transaction.
B. delete can use a where clause to determine which row(s) should be removed: DELETE operation allows the use of a WHERE clause to specify which rows should be deleted based on certain conditions.
Incorrect options are:
C: TRUNCATE does not support the use of a WHERE clause. It is designed to remove all rows from a table swiftly and cannot be conditional.
D: TRUNCATE does not leave indexes in an unusable state; it simply removes all rows.
E: TRUNCATE is a DDL command and its operation typically cannot be rolled back in many SQL database systems, including Oracle.
In your session, the NLS._DAE_FORMAT is DD- MM- YYYY.There are 86400 seconds in a day.Examine
this result:
DATE
02-JAN-2020
Which statement returns this?
SELECT TO_ CHAR(TO_ DATE(‘29-10-2019’) +INTERVAL ‘2’; MONTH + INTERVAL ‘5’; DAY -
INTERVAL ‘86410’ SECOND, ‘ DD-MON-YYYY’) AS "date"
FROM DUAL;
SELECT TO_ CHAR(TO_ DATE(‘29-10-2019’) + INTERVAL ‘3’ MONTH + INTERVAL ‘7’ DAY -
INTERVAL ‘360’ SECOND, ‘ DD-MON-YYYY’) AS "date"
FROM DUAL;
SELECT To CHAR(TO _DATE(‘29-10-2019’) + INTERVAL ‘2’ NONTH + INTERVAL ‘5’ DAY
INEERVAL ‘120’ SECOND, ‘ DD-MON-YYY) AS "date"
FROM DUAL;
SELECT-TO_CHAR(TO _DATE(‘29-10-2019’+ INTERVAL ‘2’ MONTH+INTERVAL ‘6’ DAYINTERVAL
‘120’ SECOND, ‘DD-MON-YY’) AS "daTe"
FROM DUAL;
SELECT-TO_CHAR(TO _DATE(‘29-10-2019’+ INTERVAL ‘2’ MONTH+INTERVAL ‘4’ DAYINTERVAL
‘120’ SECOND, ‘DD-MON-YY’) AS "daTe"
FROM DUAL;
To calculate the date from a given base date with intervals, Oracle allows you to add or subtract intervals from dates. Since the NLS_DATE_FORMAT is set to DD-MM-YYYY, the output is expected to be in that format.
Option B seems to calculate a date that is 3 months and 7 days ahead of October 29, 2019, and then subtracts 360 seconds (which is 6 minutes), resulting in a time that is still within the same day.
Here's how the calculation in option B would work out:
Start date: 29-10-2019
Add 3 months: 29-01-2020
Add 7 days: 05-02-2020
Subtract 360 seconds: Since it's only a few minutes, the date remains 05-02-2020.
However, this does not match the provided result of 02-JAN-2020. We would need to consider the exact amount of time being subtracted or added to find the correct answer.
But upon reviewing the options, they all have various syntax errors such as a missing TO_CHAR function, incorrect quotes, and date formats not matching the session's NLS_DATE_FORMAT. Therefore, we would need to correct these issues to find the right answer.
Examine the data in the INVOICES table:
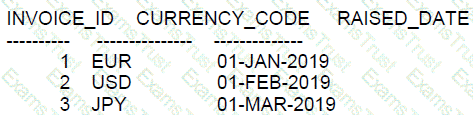
Examine the data in the CURRENCIES table:
CURRENCY_CODE
-------------
JPY
GPB
CAD
EUR
USD
Which query returns the currencies in CURRENCIES that are not present in INVOICES?
SELECT currency_ code FROM currencies
MINUS
SELECT currency_ code FROM invoices;
SELECT * FROM currencies
WHERE NOT EXISTS (
SELECT NULL FROM invoices WHERE currency_ code = currency_ code);
SELECT currency_ code FROM currencies
INTERSECT
SELECT currency_ code FROM invoices;
SELECT * FROM currencies
MINUS
SELECT * FROM invoices;
To calculate the length of employment, you would compare the current date to the HIRE_DATE and calculate the difference in years.
A. This is the correct answer. The expression calculates the number of days between the current date (SYSDATE) and the HIRE_DATE, then divides by 365 to convert it to years, and checks if it is greater than 5.
B. SYSTIMESTAMP includes a time component including fractional seconds and time zone information, making this comparison incorrect.
C. There are typos in this option (CUARENT_DATE should be CURRENT_DATE and hire_data should be hire_date). Even with the correct function and column names, CURRENT_DATE returns the current date in the session time zone, not in years.
D. There are typos in this option (SYSNAYW should be SYSDATE). Additionally, dividing by 12 incorrectly assumes that a month is equivalent to a year.
E. This is a repetition of option D with the same issues.
F. There are typos in this option (CUNACV_DATE should be CURRENT_DATE and hire_data should be hire_date). Additionally, dividing by 12 incorrectly assumes that a month is equivalent to a year.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "Date Functions"
Examine this statement which executes successfully:
Which statement will violate the CHECK constraint?
UPDATE emp80
SET department_id=90
WHERE department_id=80;
DELETE FROM emp80
WHERE department_id=90;
SELECT *
FROM emp80
WHERE department_id=80;
SELECT *
FROM emp80
WHERE department_id=90;
The CHECK constraint is generally used to limit the range of values that can be placed in a column. If a CHECK constraint exists on the department_id to only allow values such as 80 (assuming from the context provided):
A. UPDATE emp80 SET department_id=90 WHERE department_id=80: This UPDATE statement attempts to set the department_id to 90 for rows where it is currently 80. If there is a CHECK constraint preventing department_id from being anything other than 80, this statement would violate that constraint.
Incorrect options:
B: DELETE operations do not affect CHECK constraints as they do not involve modifying or setting column values.
C and D: SELECT statements do not modify data and thus cannot violate data integrity constraints like CHECK constraints.
Examine the description of the CUSTOMERS table:
Which three statements will do an implicit conversion?
SELECT * FROM customers WHERE insert_date=DATE’2019-01-01’;
SELECT * FROM customers WHERE customer_id=’0001’;
SELECT * FROM customers WHERE TO_DATE(insert_date)=DATE’2019-01-01’;
SELECT * FROM customers WHERE insert_date’01-JAN-19’;
SELECT * FROM customers WHERE customer_id=0001;
SELECT * FROM customers WHERE TO_CHAR(customer_id)=’0001’;
A: No implicit conversion; DATE is explicitly specified.
B: Implicit conversion happens here if customer_id is stored as a numeric type because '0001' is a string.
C: TO_DATE is explicitly used, so no implicit conversion occurs here.
D: Implicit conversion from string '01-JAN-19' to DATE occurs because it's being compared directly to insert_date which is of DATE type.
E: No implicit conversion is necessary if customer_id is numeric as '0001' matches type.
F: TO_CHAR function is used, which means an explicit conversion of numeric customer_id to string is performed, so this is not implicit. Hence, this is incorrect regarding implicit conversion.
Each answer has been verified with reference to the official Oracle Database 12c SQL documentation, ensuring accuracy and alignment with Oracle's specified functionalities.
Which four statements are true regarding primary and foreign key constraints and the effect they can have on table data?
Only the primary key can be defined at the column and table level.
The foreign key columns and parent table primary key columns must have the same names.
It is possible for child rows that have a foreign key to remain in the child table at the time the parent row is deleted.
A table can have only one primary key but multiple foreign keys.
Primary key and foreign key constraints can be defined at both the column and table level.
A table can have only one primary key and one foreign key.
It is possible for child rows that have a foreign key to be deleted automatically from the child table at the time the parent row is deleted
Primary and foreign key constraints are foundational to relational database design:
Option A: Incorrect. Both primary and foreign key constraints can be defined at the column or table level.
Option B: Incorrect. Foreign key columns do not need to have the same names as the corresponding primary key columns in the parent table. They must be of the same data type and size.
Option C: Incorrect. If a foreign key constraint is enforced without ON DELETE CASCADE, deleting the parent row will either prevent the delete (due to constraint) or require a prior deletion or update of the child rows.
Option D: Correct. A table can indeed have only one primary key, which uniquely identifies each row, but it can have multiple foreign keys linking to primary keys of different tables.
Option E: Correct. Both types of keys can be defined at either level, providing flexibility in how constraints are applied and enforced.
Option F: Incorrect. A table can have multiple foreign keys as stated, each referencing a different parent table.
Option G: Correct. If the ON DELETE CASCADE option is set for a foreign key, then deleting a parent row will automatically delete the corresponding child rows, maintaining referential integrity.
Which two statements are true regarding the UNION ALL operators?
NULLS are not ignored during duplicate checking.
Duplicates are eliminated automatically by the UNION ALL operator
The names of columns selected in each SELECT statement must be identical.
The number of columns selected in each SELECT statement must be identical
The output is sorted by the UNION ALL operator.
The UNION ALL operator in SQL combines the results of two or more SELECT statements into a single result set:
Option A: True. Since UNION ALL does not eliminate duplicates, it does not ignore NULLs during any duplicate checking; however, it's worth noting that UNION ALL does not perform duplicate checking at all.
Option B: False. Unlike the UNION operator, UNION ALL does not eliminate duplicates; it includes all duplicates in the output.
Option C: False. The column names do not need to be identical in each SELECT statement; however, the result set will use the column names from the first SELECT statement.
Option D: True. For UNION ALL to work correctly, the number of columns and their data types in each SELECT statement must match, but the column names can differ.
Option E: False. UNION ALL does not inherently sort the output; it merely combines the results as they are retrieved. Any sorting would need to be explicitly specified using an ORDER BY clause.
Examine the description of the transactions table:
Which two SQL statements execute successfully?
SELECT customer_id AS "CUSTOMER-ID", transaction_date AS DATE, amount+100 "DUES" from transactions;
SELECT customer_id AS 'CUSTOMER-ID',transaction_date AS DATE, amount+100 'DUES' from transactions;
SELECT customer_id CUSTID, transaction_date TRANS_DATE,amount+100 DUES FROM transactions;
SELECT customer_id AS "CUSTOMER-ID", transaction_date AS "DATE", amount+100 DUES FROM transactions;
SELECT customer id AS CUSTOMER-ID, transaction_date AS TRANS_DATE, amount+100 "DUES AMOUNT" FROM transactions;
Examining the execution of SELECT statements in Oracle SQL requires understanding correct syntax, especially regarding aliases and string literals:
Option A: Incorrect. Although the syntax might seem plausible, using DATE as an alias without quotes can lead to ambiguity because DATE is a reserved keyword in Oracle SQL. This might cause an error or unexpected behavior unless it is enclosed in double quotes.
Option B: Incorrect. Single quotes are used for string literals in SQL, not for aliasing column names. Using single quotes for aliasing, as in 'CUSTOMER-ID', 'DUES', is syntactically incorrect and will result in an error.
Option C: Correct. This statement uses valid syntax with no reserved keywords as aliases and no misuse of string literal notation. Aliases are provided without quotes, which is acceptable as long as they are not reserved words or contain special characters.
Option D: Correct. It correctly uses double quotes for aliasing, which is necessary when using reserved words like "DATE" or special characters. This is a proper use of SQL syntax for aliasing in Oracle.
Option E: Incorrect. This statement attempts to use aliases with hyphens without enclosing them in double quotes, which leads to syntax errors. Also, customer id seems to be missing an underscore or another connector to properly reference a column name, indicating a typo or error.
For these queries, ensuring correct alias syntax and avoiding reserved keywords without appropriate quoting are key elements for successful execution.
View the Exhibits and examine the structure of the COSTS and PROMOTIONS tables.
You want to display PROD IDS whose promotion cost is less than the highest cost PROD ID in a pro
motion time interval.
Examine this SQL statement:
SELECT prod id
FROM costs
WHERE promo id IN
(SELECT promo id
FROM promotions
WHERE promo_cost < ALL
(SELECT MAX (promo cost)
FROM promotions
GROUP BY (promo_end date-promo_begin_date)) );
What will be the result?
It executes successfully but does not give the required result.
It gives an error because the ALL keyword is not valid.
It gives an error because the GROUP BY clause is not valid
It executes successfully and gives the required result.
This SQL query checks for product IDs (prod_id) from the costs table where the promotion ID (promo_id) is associated with promotions whose costs are less than the maximum promotional cost of all promotions, grouped by the duration of each promotion (calculated as promo_end_date - promo_begin_date). The query is correctly written to fulfill these conditions.
The subquery SELECT MAX(promo_cost) FROM promotions GROUP BY (promo_end_date - promo_begin_date) computes the maximum cost of promotions grouped by their duration, returning the highest cost for each distinct promotion length.
The WHERE promo_cost < ALL (...) clause then filters out the promotions where the promo_cost is less than all of the maximum costs returned by the subquery, ensuring that only promo_ids associated with costs less than the highest cost for any promotion length are considered.
Since this logical structure correctly implements the given requirement, the statement executes successfully and yields the correct results.
Which two statements about INVISIBLE indexes are true?
an INVISIBLE Index consumes no storage
You can only create one INVISIBLE index on the same column list
The query optimizer never considers INVISIBLE Indexes when determining execution plans
You use AlTER INDEX to make an INVISIBLE Index VISIBLE
All INSERT, UPDATE, and DELETE statements maintain entries in the index
INVISIBLE indexes are a feature in Oracle Database 12c and later versions that allow an index to be maintained but not used by the optimizer unless explicitly hinted.
A. False. An INVISIBLE index still consumes storage space as it is maintained in the background.
B. False. There is no such restriction. You can create multiple INVISIBLE indexes on the same column list.
C. False. The optimizer can consider INVISIBLE indexes if they are hinted at in the query.
D. True. You can alter the visibility of an index using the ALTER INDEX command to make an INVISIBLE index VISIBLE.
E. True. Even though they are invisible to the optimizer by default, all DML operations such as INSERT, UPDATE, and DELETE continue to maintain the index as they would with a VISIBLE index.
Which two are true about multiple table INSERT statements?
They always use subqueries.
They can transform a row from a source table into multiple rows in a target table.
The conditional INSERT FIRST statement always inserts a row into a single table.
The conditional INSERT ALL statement inserts rows into a single table by aggregating source rows.
The unconditional INSERT ALL statement must have the same number of columns in both the source and target tables.
B: True. Multiple table insert statements, specifically the conditional INSERT ALL, can transform a single row from the source table into multiple rows in one or more target tables depending on the conditions specified in the WHEN clauses.
E: True. The unconditional INSERT ALL statement will insert rows into multiple target tables without any conditions. However, it does not require the same number of columns in both the source and target tables. The INSERT ALL syntax allows you to specify different columns for each target table into which rows will be inserted.
Multiple table insert operations allow for complex insert scenarios, where based on the data, one can insert into different tables or multiple times into the same table based on different conditions.
References:Oracle SQL reference details the use of INSERT ALL and INSERT FIRST clauses for inserting into multiple tables based on conditions specified.
Which two queries execute successfully?
SELECT INTERVAL '1' DAY - SYSDATE FROM DUAL;
SELECT SYSTIMESTAMP + INTERVAL '1' DAY FROM DUAL;
SELECT INTERVAL '1' DAY - INTERVAL '1' MINUTE FROM DUAL;
select INTERVAL '1' DAY +INTERVAL '1' MONTH FROM DUAL;
SELECT SYSDATE “INTERRVAL '1' DAY FROM DUAL;
A: This statement will not execute successfully because you cannot subtract a DAY interval from a DATE directly. SYSDATE needs to be cast to a TIMESTAMP first.
B: This statement is correct. It adds an interval of '1' DAY to the current TIMESTAMP.
C: This statement is correct. It subtracts an interval of '1' MINUTE from '1' DAY.
D: This statement will not execute successfully. In Oracle, you cannot add intervals of different date fields (DAY and MONTH) directly.
E: This statement has a syntax error with the quotes around INTERVAL and a misspelling, it should be 'INTERVAL'.
Oracle Database 12c SQL supports interval arithmetic as described in the SQL Language Reference documentation.
Examine the description of the transactions table:

Which two SQL statements execute successfully?
SELECT customer_id AS "CUSTOMER-ID", transaction_date AS DATE, amount+100 "DUES" from transactions;
SELECT customer_id AS 'CUSTOMER-ID',transaction_date AS DATE, amount+100 'DUES' from transactions;
SELECT customer_id CUSTID, transaction_date TRANS_DATE,amount+100 DUES FROM transactions;
SELECT customer_id AS "CUSTOMER-ID", transaction_date AS "DATE", amount+100 DUES FROM transactions;
SELECT customer id AS CUSTOMER-ID, transaction_date AS TRANS_DATE, amount+100 "DUES AMOUNT" FROM transactions;
A. True, this statement will execute successfully. In Oracle SQL, column aliases can be given in double quotes which allows the use of special characters like a hyphen. Additionally, you can perform arithmetic operations such as amount+100 directly in the SELECT clause to return increased values of amount.
C. True, this statement is also valid. It does not use any special characters or reserved keywords as aliases that would require double quotes. The arithmetic operation is the same as in option A, which is permissible.
For B, D, and E, the reasons for failure are: B. In Oracle SQL, single quotes are used for string literals, not for column aliases. Therefore, using single quotes around 'CUSTOMER-ID' and 'DUES' will result in an error. D. The word "DATE" is a reserved keyword in Oracle SQL. When used as a column alias without double quotes, it will lead to an error. In this statement, although "DATE" is in double quotes, it's a best practice to avoid using reserved keywords as aliases. E. There are syntax errors in the statement. "customer id" should be "customer_id", and the alias "CUSTOMER-ID" should be enclosed in double quotes if special characters are used. Also, "DUES AMOUNT" as an alias should be in double quotes to be valid because it contains a space.
References:
Oracle documentation on column aliases: Oracle Database SQL Language Reference
Oracle reserved words: Oracle Database SQL Language Reserved Words
Which three are true about scalar subquery expressions?
A scalar subquery expression that returns zero rows evaluates to zoro
They cannot be used in the values clause of an insert statement*
They can be nested.
A scalar subquery expression that returns zero rows evaluates to null.
They cannot be used in group by clauses.
They can be used as default values for columns in a create table statement.
Scalar subquery expressions are used in Oracle SQL to return a single value from a subquery.
Option C: They can be nested.
Scalar subqueries can indeed be nested within another scalar subquery, provided each subquery returns a single value.
Option D: A scalar subquery expression that returns zero rows evaluates to null.
According to Oracle documentation, if a scalar subquery returns no rows, the result is a NULL value, not zero or any other default.
Option F: They can be used as default values for columns in a create table statement.
Scalar subqueries can be specified in the DEFAULT clause of a column in a CREATE TABLE statement to dynamically assign default values based on the result of the subquery.
Options A, B, and E are incorrect based on Oracle SQL standards and functionalities.
Examine this partial command:

Which two clauses are required for this command to execute successfully?
the DEFAULT DIRECTORY clause
the REJECT LIMIT clause
the LOCATION clause
the ACCESS PARAMETERS clause
the access driver TYPE clause
In Oracle Database 12c, when creating an external table using the CREATE TABLE ... ORGANIZATION EXTERNAL statement, there are certain clauses that are mandatory for the command to execute successfully.
Statement C, the LOCATION clause, is required. The LOCATION clause specifies one or more external data source locations, typically a file or a directory that the external table will read from. Without this, Oracle would not know where to find the external data for the table.
Statement E, the access driver TYPE clause, is also required. The access driver tells Oracle how to interpret the format of the data files. The most common access driver is ORACLE_LOADER, which allows the reading of data files in a format compatible with the SQL*Loader utility. Another option could be ORACLE_DATAPUMP, which reads data in a Data Pump format.
Statements A, B, and D are not strictly required for the command to execute successfully, although they are often used in practice:
A, the DEFAULT DIRECTORY clause, is not mandatory if you have specified the full path in the LOCATION clause, but it is a best practice to use it to avoid hard-coding directory paths in the LOCATION clause.
B, the REJECT LIMIT clause, is optional and specifies the maximum number of errors to allow during the loading of data. If not specified, the default is 0, meaning the load will fail upon the first error encountered.
D, the ACCESS PARAMETERS clause, is where one would specify parameters for the access driver, such as field delimiters and record formatting details. While it is common to include this clause to define the format of the external data, it is not absolutely required for the command to execute; defaults would be used if this clause is omitted.
For reference, you can find more details in the Oracle Database SQL Language Reference for version 12c, under the CREATE TABLE statement for external tables.
Which two are true about creating tables in an Oracle database?
A create table statement can specify the maximum number of rows the table will contain.
The same table name can be used for tables in different schemas.
A system privilege is required.
Creating an external table will automatically create a file using the specified directory and file name.
A primary key constraint is manadatory.
Regarding creating tables in an Oracle database:
B. The same table name can be used for tables in different schemas: In Oracle, a schema is essentially a namespace within the database; thus, the same table name can exist in different schemas without conflict, as each schema is distinct.
C. A system privilege is required: To create tables, a user must have the necessary system privileges, typically granted explicitly or through roles such as CREATE TABLE or administrative privileges depending on the environment setup.
Incorrect options for all three repeated questions:
A: Oracle SQL does not allow specifying the maximum number of rows directly in a CREATE TABLE statement; this is controlled by storage allocation and database design rather than table creation syntax.
D: Creating an external table does not create the physical file. It merely creates a table structure that allows access to data stored in an external file specified in the directory; the file itself must already exist or be managed outside of Oracle.
E: A primary key constraint is not mandatory for creating tables. While it is a common practice to define a primary key to enforce entity integrity, it is not required by the Oracle SQL syntax for table creation.
These answers and explanations are aligned with Oracle Database 12c SQL documentation and standard practices.
Which three statements are true about performing DML operations on a view with no INSTEAD OF triggers defined?
Insert statements can always be done on a table through a view.
The WITH CHECK clause has no effect when deleting rows from the underlying table through the view.
Delete statements can always be done on a table through a view.
Views cannot be used to add rows to an underlying table If the table has columns with NOT NULL constraints lacking default values which are not referenced in the defining query of the view.
Views cannot be used to query rows from an underlying table if the table has a PRIMARY KEY and the primary key columns are not referenced in the defining query of the view.
Views cannot be used to add or modify rows in an underlying table If the defining query of the view contains the DISTINCT keyword.
A: Insert statements can be done through a view only if all NOT NULL constraints without default values of the base table are included in the view. Therefore, statement A is incorrect.
B: The WITH CHECK OPTION ensures that all DML operations performed through the view result in data that conforms to the view’s defining query. It affects DELETE as well as other DML operations, making statement B incorrect.
C: Similar to inserts, DELETE operations can be done through a view unless the view contains constructs that inherently do not support it, such as certain joins or set operations. Statement C is generally incorrect.
D: If a view does not include all NOT NULL columns without defaults of the underlying table, it cannot be used to add rows because the missing columns will lack values. This makes statement D correct.
E: This statement is incorrect as primary keys do not affect querying through views; they affect insert and update operations where uniqueness and non-nullability are enforced.
F: If the defining query of a view includes DISTINCT, the view generally cannot be used to perform update or insert operations as it may not be able to uniquely determine rows. This makes statement F correct.
Examine these statements and results:
SQL> SELECT COUNT(*) FROM emp
COUNT(*)
---------------------
14
sQL> CREATE GLOBAL TEMPORARY TABLE t emp As SELECT * FROM emp;
Table created
SQL> INSERT INTo temp SELECT * FROM emp;
14 rows created
SQL> COMMIT:
Commit complete*
SQL> INSERT INTo temp SELECT * EROM emp;
14. rows created
SQL> SELECT COUNT(*) FROM t emp
How many rows are retrieved by the last query?
28
0
14
42
Global temporary tables in Oracle Database are designed to hold temporary data for the duration of a session or a transaction.
Given that the global temporary table is created and then populated twice from the emp table without any mention of data deletion, one would initially think the count would be 28, since 14 rows are inserted twice. However, if the temporary table was created with the default ON COMMIT DELETE ROWS option, the rows are deleted at the end of the transaction, which is signified by the COMMIT operation.
Thus, after the first COMMIT, the temporary table would be empty. After the second INSERT, another 14 rows would be added. So, the last query would retrieve 14 rows unless a DELETE operation was committed.
Examine the description of the ORDERS table:

Which three statements execute successfully?
(SELECT * FROM orders
UNION ALL
SELECT* FROM invoices) ORDER BY order _id;
SELECE order _id, order _ date FRON orders
LNTERSECT
SELECT invoice_ id, invoice_ id, order_ date FROM orders
SELECT order_ id, invoice_ data order_ date FROM orders
MINUS
SELECT invoice_ id, invoice_ data FROM invoices ORDER BY invoice_ id;
SELECT * FROM orders ORDER BY order_ id
INTERSEOT
SELECT * FROM invoices ORDER BY invoice_ id;
SELECT order_ id, order_ data FROM orders
UNION ALL
SELECT invoice_ id, invoice_ data FROM invoices ORDER BY order_ id;
SELECT * FROM orders
MINUS
SELECT * FROM INVOICES ORDER BY 1
SELECT * FROM orders ORDER BY order_ id
UNION
SELECT * FROM invoices;
In Oracle SQL, set operations like UNION, UNION ALL, INTERSECT, and MINUS can be used to combine results from different queries:
Option A:
Combining results using UNION ALL followed by ORDER BY will execute successfully because UNION ALL allows duplicate rows and ORDER BY can be used to sort the combined result set.
Option E:
Similar to option A, UNION ALL combines all rows from the two selects and allows ordering of the results.
Option G:
UNION combines the results from two queries and removes duplicates, and ORDER BY can be used to sort the final result set.
Options B, C, D, and F are incorrect because:
Option B: You cannot intersect different columns (ORDER_ID with INVOICE_ID).
Option C: Incorrect column names and syntax with ORDER BY.
Option D: ORDER BY cannot be used before a set operator like INTERSECT.
Option F: ORDER BY cannot be used directly after a MINUS operator without wrapping the MINUS operation in a subquery.
Which two statements are true about conditional INSERT ALL?
Each row returned by the subquery can be inserted into only a single target table.
It cannot have an ELSE clause.
The total number of rows inserted is always equal to the number of rows returned by the subquery
A single WHEN condition can be used for multiple INTO clauses.
Each WHEN condition is tested for each row returned by the subquery.
For conditional INSERT ALL in Oracle Database 12c:
D. A single WHEN condition can be used for multiple INTO clauses. This is true. A single WHEN condition in a multi-table insert can direct the insertion of a single row source into multiple target tables.
E. Each WHEN condition is tested for each row returned by the subquery. True, each row from the subquery is evaluated against each WHEN condition to determine into which table(s) the row should be inserted.
Options A, B, and C are incorrect:
A is incorrect because a row can indeed be directed into multiple tables based on the conditions.
B is incorrect as INSERT ALL can include an ELSE clause to handle rows that do not meet any of the specified conditions.
C is incorrect because not every row from the subquery necessarily results in a row insertion; it depends on the conditions being met.
Which two are true about external tables that use the ORACLE _DATAPUMP access driver?
Creating an external table creates a directory object.
When creating an external table, data can be selected only from a table whose rows are stored in database blocks.
When creating an external table, data can be selected from another external table or from a table whose rows are stored in database blocks.
Creating an external table creates a dump file that can be used by an external table in the same or a different database.
Creating an external table creates a dump file that can be used only by an external table in the same database.
External tables using the ORACLE_DATAPUMP access driver have specific characteristics:
C. Creating an external table using the ORACLE_DATAPUMP access driver allows you to select data from other tables, including another external table or a regular table whose rows are stored in database blocks.
A, B, D, and E are incorrect. Specifically:
A is incorrect because creating an external table does not automatically create a directory object; the directory object must exist prior to or be created separately.
B is incorrect as it limits the creation to tables stored in database blocks, which is not a restriction.
D is incorrect because creating an external table does not create a dump file; it reads from an existing dump file created by Data Pump.
E is also incorrect because the dump file is not created as part of the external table creation process.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "CREATE TABLE" for External Tables
Examine the description of the CUSTOMERS table:

Which two SELECT statements will return these results:
CUSTOMER_ NAME
--------------------
Mandy
Mary
SELECT customer_ name FROM customers WHERE customer_ name LIKE ' % a % ’ ;
SELECT customer_ name FROM customers WHERE customer name LIKE 'Ma%' ;
SELECT customer_ name FROM customers WHERE customer_ name='*Ma*';
SELECT customer_ name FROM customers WHERE UPPER (customer_ name ) LIKE 'MA*. ;
SELECT customer_ name FROM customers WHERE customer name LIKE 'Ma*';
SELECT customer_ name FROM customers WHERE UPPER (customer name) LIKE 'MA&';
SELECT customer_ name FROM customers WHERE customer_ name KIKE .*Ma*';
The SQL LIKE operator is used in a WHERE clause to search for a specified pattern in a column. Here are the evaluations of the options:
A: The pattern ' % a % ’ will match any customer names that contain the letter 'a' anywhere in the name, not necessarily those starting with 'Ma'.
B: This is correct as 'Ma%' will match any customer names that start with 'Ma'.
C: In SQL, the wildcard character is '%' not '*', therefore, the pattern 'Ma' is incorrect.
D: This is the correct syntax. 'UPPER (customer_ name ) LIKE 'MA%'' will match customer names starting with 'Ma' in a case-insensitive manner.
E: Again, '*' is not a valid wildcard character in SQL.
F: The character '&' is not a wildcard in SQL.
G: The operator 'KIKE' is a typo, and '.Ma' is not valid SQL pattern syntax.
Which two are true about queries using set operators (UNION, UNION ALL, INTERSECT and MINUS)?
There must be an equal number of columns in each SELECT list.
The name of each column in the first SELECT list must match the name of the corresponding column in each subsequent SELECT list.
Each SELECT statement in the query can have an ORDER BY clause.
None of the set operators can be used when selecting CLOB columns.
The FOR UPDATE clause cannot be specified.
A. True. When using set operators, the number and order of columns must be the same in all SELECT statements involved in the query. The data types of those columns must also be compatible.
E. True. The FOR UPDATE clause cannot be specified in a subquery or a SELECT statement that is combined with another SELECT statement by using a set operator.
B is incorrect because the column names do not need to match; only the number and data types of the columns must be compatible. C is incorrect because only the final SELECT statement in the sequence of UNION/INTERSECT/MINUS operations can have an ORDER BY clause. D is incorrect because, as of Oracle 12c, UNION ALL can be used with CLOB columns, but UNION, INTERSECT, and MINUS cannot.
Examine thee statements which execute successfully:
CREATE USER finance IDENTIFIED BY pwfin;
CREATE USER fin manager IDENTIETED BY pwmgr;
CREATE USER fin. Clerk IDENTIFIED BY pwclerk;
GRANT CREATE SESSON 20 finance, fin clerk;
GRANT SELECT ON scott. Emp To finance WITH GRANT OPTION;
CONNECT finance/pwfin
GRANT SELECT ON scott. emp To fin_ _clerk;
Which two are true?
Dropping user FINANCE will automatically revoke SELECT on SCOTT. EMP from user FIN _ CLERK
Revoking SELECT on SCOTT. EMP from user FINANCE will also revoke the privilege from user FIN_ CLERK.
User FINANCE can grant CREATE SESSION to user FIN MANAGER.
User FIN CLERK can grant SELECT on SCORT, ENP to user FIN MANAGER.
User FINANCE is unable to grant ALL on SCOTT.ENP to FIN MANAGER.
Regarding privileges in Oracle:
Option A: Dropping user FINANCE will automatically revoke SELECT on SCOTT.EMP from user FIN_CLERK.
Dropping a user will revoke all privileges that user has granted to others.
Option B: Revoking SELECT on SCOTT.EMP from user FINANCE will also revoke the privilege from user FIN_CLERK.
Since FINANCE granted SELECT on SCOTT.EMP to FIN_CLERK with grant option, revoking the privilege from FINANCE will also cascade and revoke it from FIN_CLERK.
Options C, D, and E are incorrect because:
Option C: User FINANCE can grant privileges it owns, but CREATE SESSION is a system privilege; unless FINANCE has the 'WITH ADMIN OPTION' for CREATE SESSION, it cannot grant this privilege.
Option D: User FIN_CLERK can only grant privileges to others if it has been given those privileges with the 'WITH GRANT OPTION' and it was not given in this case.
Option E: User FINANCE can grant privileges on SCOTT.EMP to other users only if it has those privileges with 'WITH GRANT OPTION'. If the privilege was just SELECT with GRANT OPTION, it cannot grant ALL privileges.
Which two statements are true about Oracle databases and SQL?
Updates performed by a database user can be rolled back by another user by using the ROLLBACK command.
The database guarantees read consistency at select level on user-created tablers.
When you execute an UPDATE statement, the database instance locks each updated row.
A query can access only tables within the same schema.
A user can be the owner of multiple schemas In the same database.
B. True. Oracle databases guarantee read consistency at the transaction level, meaning that each query can only see data that has been committed before the query began executing.
C. True. When an UPDATE statement is executed, Oracle locks each row as it is updated to prevent other transactions from modifying it until the transaction is committed or rolled back.
A is incorrect because updates made by one user cannot be rolled back by another user. D is incorrect because a query can access tables in other schemas if proper permissions are granted. E is incorrect because a user can own only one schema, which has the same name as the user in an Oracle database.
Which two statements are true about views?
Views can be indexed.
Theethi CHEcK clause prevents certalin rows from being updated or inserted in the underying table through the view.
Tables in the defining query of a view must always exist in order to create the view.
Views can be updated without the need to re-grant privileges on the view.
The wITH CHECK clause prevents certain rows from being displayed when querying the view.
Views in Oracle have specific properties regarding how they can be used and what limitations apply to them:
A. Oracle does not allow indexing directly on views. However, a view can display data from indexed tables.
B. The WITH CHECK OPTION clause on a view prevents DML operations that would result in rows that do not satisfy the view’s filter criteria. It doesn't prevent certain rows from being updated or inserted in the underlying table through the view per se.
C. The tables (or other views) referenced in the creating query of a view must exist at the time the view is created, making this statement true.
D. Views do not require privileges to be re-granted when the view is updated; they are separate from the underlying object privileges, making this statement true.
E. The WITH CHECK OPTION clause is used to ensure that all data modifications through the view are consistent with the view's defining query, not to prevent rows from being displayed.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "CREATE VIEW"
Oracle Database Concepts, 12c Release 1 (12.1): "Views"
Which two statements are true about the results of using the intersect operator in compound queries?
intersect ignores nulls.
Reversing the order of the intersected tables can sometimes affect the output.
Column names in each select in the compound query can be different.
intersect returns rows common to both sides of the compound query.
The number of columns in each select in the compound query can be different.
C. True, the names of the columns in each SELECT statement of an INTERSECT query do not need to match, as long as the data types and order of the columns correspond.D. True, the INTERSECT operator returns only the rows that are common to both SELECT statements, effectively acting as a set intersection of the results from both queries.
References:
Oracle documentation on INTERSECT operator: Oracle Database SQL Language Reference
Detailed behavior of INTERSECT: Oracle Compound Queries
Examine the description or the BOOKS_TRANSACTIONS table:

FOR customers whose income level has a value, you want to display the first name and due amount as 5% of their credit limit. Customers whose due amount is null should not be displayed.
Which query should be used?
SELECT cust_first_name, cust_credit_limit * . 05 AS DUE AMOUNT
FROM customers
WHERE cust income_level !=NULL
AND cust credit_level !=NULL;
SELECT cust_first_name, cust_credit_limit * . 05 AS DUE AMOUNT
FROM customers
WHERE cust income_level IS NOT NULL
AND due_amount IS NOT NULL;
SELECT cust_first_name, cust_credit_limit * . 05 AS DUE AMOUNT
FROM customers
WHERE cust income_level <> NULL
AND due_amount <> NULL;
SELECT cust_first_name, cust_credit_limit * . 05 AS DUE AMOUNT
FROM customers
WHERE cust_income_level IS NOT NULL
AND cust_credit_limit IS NOT NULL;
SELECT cust_first_name, cust_credit_limit * . 05 AS DUE AMOUNT
FROM customers
WHERE cust income_level !=NULL
AND due_amount !=NULL;
D: True. This query selects the first name and calculates the due amount as 5% of the credit limit from the customers table where the income level is not null and the credit limit is also not null. The IS NOT NULL operator is used to check for non-null values correctly.
The IS NOT NULL operator is the correct way to check for non-null values in SQL. The <> NULL and != NULL comparisons are incorrect because NULL is not a value that can be compared using these operators; it represents the absence of a value.
There is no due_amount column in the customers table according to the structure provided, so any WHERE clause referencing due_amount is irrelevant and incorrect. The due_amount is a derived column in the SELECT clause.
The correct syntax to check for non-null values is IS NOT NULL, which is used in the WHERE clause of the correct answer.
References:
The use of IS NOT NULL in the WHERE clause to filter out null values is documented in Oracle's SQL reference.
NULL comparisons must be done with IS NULL or IS NOT NULL for correct logical evaluation in SQL.
Examine this incomplete query:
SELECT DATA’2019-01-01’+
FROM DUAL;
Which three clauses can replace
INTERVAL ‘12:00’
INTERVAL’0,5’DAY
INTERVAL’12’ HOUR
INTERVAL’720’MINUTE
INTERVAL’0 12’DAY TO HOUR
INTERVAL’11:60’HOUR TO MINUTE
In Oracle SQL, adding hours to a date can be done using the INTERVAL keyword with appropriate clauses:
Option C: INTERVAL '12' HOUR
Adds exactly 12 hours to a date.
Option D: INTERVAL '720' MINUTE
Since 720 minutes equal 12 hours, this correctly adds 12 hours to a date.
Option F: INTERVAL '11:60' HOUR TO MINUTE
This interval represents 11 hours and 60 minutes, which effectively adds up to 12 hours.
Options A, B, and E contain incorrect syntax or do not match the required addition of 22 hours as specified in the question.
You execute this command:
ALTER TABLE employees SET UNUSED (department_id);
Which two are true?
A query can display data from the DEPARTMENT_ID column.
The storage space occupied by the DEPARTMENT_ID column is released only after a COMMIT is issued.
The DEPARTMENT_ID column is set to null for all tows in the table
A new column with the name DEPARTMENT_ID can be added to the EMPLOYEES table.
No updates can be made to the data in the DEPARTMENT_ID column.
The DEPARTMENT_ID column can be recovered from the recycle bin
D. True, after setting the DEPARTMENT_ID column to UNUSED, you can add a new column with the name DEPARTMENT_ID to the EMPLOYEES table. The UNUSED clause does not delete the column, it only marks it as no longer being used.E. True, once a column is marked as UNUSED, you cannot make updates to it. It becomes inaccessible for DML operations.
A, B, C, and F are not correct because: A. Once a column is set to UNUSED, it is not available for queries. B. The storage space is not immediately released after issuing a COMMIT; instead, the actual removal and space reclamation happen when you subsequently issue the DROP UNUSED COLUMNS operation. C. The DEPARTMENT_ID column is not set to null; instead, it's marked as UNUSED, which means it is no longer available for use. F. UNUSED columns are not placed into the recycle bin; they are just marked for deletion, and space can be reclaimed with the DROP UNUSED COLUMNS command.
References:
Oracle documentation on ALTER TABLE: Oracle Database SQL Language Reference
Understanding ALTER TABLE SET UNUSED: Oracle Database Administrator’s Guide
Which two are true about the precedence of opertors and condtions
+ (addition) has a higher order of precedence than * (mliplpition)
NOT has a higher order of precedence than AND and OR in a condition.
AND and OR have the same order of precedence in a condition
Operators are evaluated before conditions.
|| has a higher order of precedence than +(addition)
Regarding the precedence of operators and conditions in Oracle Database 12c:
Option B: NOT has a higher order of precedence than AND and OR in a condition.
In logical operations, NOT is evaluated first, followed by AND and then OR.
Option E: || has a higher order of precedence than +(addition).
The string concatenation operator || has a higher precedence than the arithmetic + operator.
Options A, C, and D are incorrect because:
Option A: Multiplication (*) has a higher precedence than addition (+).
Option C: AND has a higher precedence than OR.
Option D: Conditions (which may contain operators) are evaluated according to the rules of operator precedence.
Examine these requirements:
1. Display book titles for books purchased before January 17, 2007 costing less than 500 or more than 1000.
2. Sort the titles by date of purchase, starting with the most recently purchased book.
Which two queries can be used?
SELECT book_title FROM books WHERE (price< 500 OR >1000) AND (purchase date< '17-JAN-2007') ORDER BY purchase date DESC;
SELECT book_title FROM books WHERE (price IN (500, 1000)) AND (purchase date < '17-JAN-2007') ORDER BY purchase_date ASC;
SELECT book_title FROM books WHERE (price NOT BETWEEN 500 AND 1000) AND (purchase_date< '17-JAN-2007') ORDER BY purchase_date DESC;
SELECT book_title FROM books WHERE (price BETWEEN 500 AND 1000) AND (purchase_date<'17-JAN-2007') ORDER BY purchase_date;
The requirements specify that we need to select book titles based on a price condition and a date condition, and then sort the results by the date of purchase.
A. This query will not execute successfully because there is a syntax error in the price condition. It should be price < 500 OR price > 1000.
B. This query is incorrect. The requirement specifies that the price must be less than 500 or more than 1000, not in a list of values.
C. This query is correct. It selects books where the price is not between 500 and 1000 (thus, less than 500 or more than 1000) and the purchase date is before January 17, 2007, ordered by purchase date in descending order.
D. This query is incorrect because it selects books with prices between 500 and 1000, which is not what the requirement specifies.
Which two will execute successfully?
SELECT COALESCR('DATE', SYSDATE) FROM DUAL;
SELECT NVL('DATE',SYSDATE) FROM DUAL;
SELECT COALESCE(O,SYSDATE) TRCH DUAL;
SELECT NVL('DATE',200) FROM (SELECT NULL AS “DATE” FROM DUAL);
SELECT COALESCE('DATE',SYSDATE) FROM (SELECT NULL AS “DATE” FROM DUAL) ;
D. True. The NVL function can replace a NULL value with a specified value, and it does not require the data types to match exactly, allowing implicit conversion where possible. Here, 'DATE' is a string literal, and 200 is a number, and since the selected column is NULL, NVL will return 200.
The other options are incorrect because the COALESCE function requires all arguments to be of the same data type or at least compatible types that Oracle can implicitly convert. In A and E, the use of COALESCE with a string literal 'DATE' and SYSDATE (which is a date type) is not compatible without explicit conversion. Option C has a typo (TRCH instead of FROM) and is mixing data types incorrectly.
Examine the description of the ORDER_ITEMS table:

Examine this incomplete query:
SELECT DISTINCT quantity * unit_price total_paid FROM order_items ORDER BY
Which two can replace
quantity
quantity, unit_price
total_paid
product_id
quantity * unit_price
In a SELECT statement with DISTINCT, the ORDER BY clause can only order by expressions that are part of the SELECT list.
A. quantity alone is not sufficient to replace <clause> as it is not included in the SELECT list after DISTINCT.
B. This option can successfully replace <clause> because both quantity and unit_price are used in the SELECT expression, and thus their individual values are valid for the ORDER BY clause.
C. total_paid is an alias for the expression quantity * unit_price, but it cannot be used in the ORDER BY clause because Oracle does not allow aliases of expressions in DISTINCT queries to be used in ORDER BY.
D. product_id is not included in the SELECT list after DISTINCT and thus cannot be used in ORDER BY.
E. The expression quantity * unit_price is exactly what is selected, so it can replace <clause> and the query will complete successfully.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "ORDER BY Clause"
Which two statements are true about single row functions?
CONCAT: can be used to combine any number of values
FLOOR: returns the smallest integer greater than or equal to a specified number
CEIL: can be used for positive and negative numbers
TRUNC: can be used with NUMBER and DATE values
MOD: returns the quotient of a division operation
Regarding single row functions in Oracle Database 12c:
C. CEIL: can be used for positive and negative numbers. This is true. The CEIL function rounds a number up to the nearest integer, and it works for both positive and negative values.
D. TRUNC: can be used with NUMBER and DATE values. This is correct. The TRUNC function can truncate numbers or dates to a specified precision.
Options A, B, and E are incorrect:
A is incorrect because CONCAT function typically concatenates two strings; to concatenate more, you must nest CONCAT calls or use the || operator.
B is incorrect because FLOOR returns the largest integer less than or equal to the specified number, not greater.
E is incorrect because MOD returns the remainder of a division operation, not the quotient.
Choose two
Examine the description of the PRODUCT DETALS table:

PRODUCT_ID can be assigned the PEIMARY KEY constraint.
EXPIRY_DATE cannot be used in arithmetic expressions.
EXPIRY_DATE contains the SYSDATE by default if no date is assigned to it
PRODUCT_PRICE can be used in an arithmetic expression even if it has no value stored in it
PRODUCT_PRICE contains the value zero by default if no value is assigned to it.
PRODUCT_NAME cannot contain duplicate values.
A. PRODUCT_ID can be assigned the PRIMARY KEY constraint.
In Oracle Database 12c, a PRIMARY KEY constraint is a combination of a NOT NULL constraint and a unique constraint. It ensures that the data contained in a column, or a group of columns, is unique among all the rows in the table and not null. Given the PRODUCT_ID is marked as NOT NULL, it is a candidate for being a primary key because we can assume that it is intended to uniquely identify each product in the table.
Which statements are true regarding primary and foreign key constraints and the effect they can have on table data?
A table can have only one primary key but multiple foreign keys.
It is possible for child rows that have a foreign key to remain in the child table at the time the parent row is deleted.
Primary key and foreign key constraints can be defined at both the column and table level.
Only the primary key can be defined the column and table level.
It is possible for child rows that have a foreign key to be deleted automatically from the child table at the time the parent row is deleted.
The foreign key columns and parent table primary key columns must have the same names.
A table can have only one primary key and one foreign key.
Regarding primary and foreign key constraints:
A. A table can have only one primary key but multiple foreign keys. This is true. A table is constrained to have only one primary key, which can consist of multiple columns, but can have several foreign keys referencing primary keys in other tables.
C. Primary key and foreign key constraints can be defined at both the column and table level. True. Constraints can be defined inline with the column definition or separately at the end of the table definition.
E. It is possible for child rows that have a foreign key to be deleted automatically from the child table at the time the parent row is deleted. This is also true if the foreign key is defined with the ON DELETE CASCADE option.
Options B, D, F, and G are incorrect:
B is incorrect because if a parent row is deleted, the child rows cannot remain without violating the integrity unless the foreign key is defined with ON DELETE SET NULL or similar behavior.
D is incorrect because both primary and foreign key constraints can be defined at both levels.
F is incorrect as the names of the foreign key columns do not need to match the primary key column names.
G is incorrect as a table can have multiple foreign keys.
Evaluate the following SQL statement
SQL>SELECT promo_id, prom _category FROM promotions
WHERE promo_category=’Internet’ ORDER BY promo_id
UNION
SELECT promo_id, promo_category FROM Pomotions
WHERE promo_category = ‘TV’
UNION
SELECT promoid, promocategory FROM promotions WHERE promo category=’Radio’
Which statement is true regarding the outcome of the above query?
It executes successfully and displays rows in the descend ignore of PROMO CATEGORY.
It produces an error because positional, notation cannot be used in the ORDER BY clause with SBT operators.
It executes successfully but ignores the ORDER BY clause because it is not located at the end of the compound statement.
It produces an error because the ORDER BY clause should appear only at the end of a compound query-that is, with the last SELECT statement.
C. It executes successfully but ignores the ORDER BY clause because it is not located at the end of the compound statement: The ORDER BY clause in a compound query using UNION should be placed at the very end of the final SELECT statement. Since it's located with the first SELECT, it will be ignored.
In your session NLS_ DATE_ FORMAT is set to DD–MON_RR.
Which two queries display the year as four digits?
SELECT TO_DATE(TO_CHAR(SYSDATE,'MM/DD/YYYY'),'MM/DD/YYYY') FROM DUAL;
SELECT TO_CHAR (ADD_MONTHS (SYSDATE,6)) FROM DUAL;
SELECT TO_DATE (SYSDATE, 'RRRR-MM-DD') FROM DUAL;
SELECT TO_DATE (ADD_MONTHS(SYSDATE,6), 'dd-mon-yyyy') FROM DUAL;
SELECT TO_CHAR (SYSDATE, 'MM/DD/YYYY') FROM DUAL;
SELECT TO_CHAR (ADD_MONTHS (SYSDATE, 6), 'dd-mon-yyyy') FROM DUAL;
A. True. The TO_CHAR function will convert SYSDATE to a string using the format 'MM/DD/YYYY', which displays the year as four digits. Then TO_DATE will convert this string back to a date without changing its appearance because the format matches.
E. True. The TO_CHAR function with the format 'MM/DD/YYYY' will display the date with the year as four digits, regardless of the NLS_DATE_FORMAT setting.
B, C, D, and F are incorrect because they either do not specify the format model needed to display the year as four digits or use TO_DATE which does not format the output but rather interprets the input.

Which two queries will result in an error?
SELECT FIRST_NAME LAST_NAME FROM EMPLOYEES;
SELECT FIRST_NAME,LAST_NAME FROM EMPLOYEES;
SELECT LAST_NAME,12 * SALARY AS ANNUAL_SALARY
FROM EMPLOYEES
WHERE ANNUAL_SALARY > 100000
ORDER BY 12 * SALARY ;
SELECT LAST_NAME,12 * SALARY AS ANNUAL_SALARY
FROM EMPLOYEES
WHERE 12 * SALARY > 100000
ORDER BY ANNUAL_SALARY;
SELECT LAST_NAME,12 * SALARY AS ANNUAL_SALARY
FROM EMPLOYEES
WHERE 12 * SALARY > 100000
ORDER BY 12 * SALARY;
SELECT LAST_NAME,12 * SALARY AS ANNUAL_SALARY
FROM EMPLOYEES
WHERE ANNUAL_SALARY > 100000
ORDER BY ANNUAL_SALARY;
In Oracle SQL, the following syntactical rules apply:
A. This query will result in an error because there is no comma separating the column names FIRST_NAME and LAST_NAME. The correct syntax should include a comma to separate the column names in the SELECT list.
B. This query is correctly formatted with a comma separating the column names, so it will not result in an error.
C. This query will result in an error because an alias defined in the SELECT list (ANNUAL_SALARY) cannot be used in the WHERE clause of the same query level. It must be repeated in the WHERE clause as 12 * SALARY.
D. This query will execute successfully because 12 * SALARY is directly used in the WHERE clause, and ANNUAL_SALARY is used in the ORDER BY clause, which is allowed.
E. This query is correct and will not result in an error. It uses 12 * SALARY in both the WHERE and ORDER BY clauses.
F. Similar to option C, this query will execute successfully because ANNUAL_SALARY is correctly used in the ORDER BY clause, and the WHERE clause does not attempt to reference the alias.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "Database Object Names and Qualifiers"
Which three statements are true about time zones, date data types, and timestamp data types in an Oracle database?
The DBTIMEZONE function can return an offset from Universal Coordinated Time (UTC)
A TIMESTAMP WITH LOCAL TIMEZONE data type column is stored in the database using the time zone of the session that inserted the row
A TIMESTAMP data type column contains information about year, month, and day
The SESSIONTIMEZONE function can return an offset from Universal Coordinated Time (UTC)
The CURRENT_TIMESTAMP function returns data without time zone information
A: True. The DBTIMEZONE function returns the database's time zone offset from UTC (Coordinated Universal Time). In Oracle 12c, DBTIMEZONE can return the time zone of the database in terms of a region name or as a numeric offset from UTC. This is stated in the Oracle documentation for managing time zones.
B: True. TIMESTAMP WITH LOCAL TIME ZONE is a data type that adjusts the data stored in the database to the time zone of the session that is querying or inserting the data. When data is stored, Oracle converts it from the session time zone to UTC, and upon retrieval, it converts it back to the session time zone. This is a feature designed to allow the same data to be viewed in different time zones automatically, making it highly useful in global applications.
D: True. SESSIONTIMEZONE function returns the time zone offset of the current session from UTC. This is useful for understanding and managing data conversions in applications that are used across different time zones. The time zone can be displayed as an offset from UTC or as a named region depending on the environment settings.
Choose the best answer.
Examine the description of the EMPLOYEES table:

Which query is valid?
SELECT dept_id, join_date,SUM(salary) FROM employees GROUP BY dept_id, join_date;
SELECT depe_id,join_date,SUM(salary) FROM employees GROUP BY dept_id:
SELECT dept_id,MAX(AVG(salary)) FROM employees GROUP BY dept_id;
SELECT dept_id,AVG(MAX(salary)) FROM employees GROUP BY dapt_id;
In Oracle 12c SQL, the GROUP BY clause is used to arrange identical data into groups with the GROUP BY expression followed by the SELECT statement. The SUM() function is then used to calculate the sum for each grouped record on a specific column, which in this case is the salary column.
Option A is valid because it correctly applies the GROUP BY clause. Both dept_id and join_date are included in the SELECT statement, which is a requirement when using these columns in conjunction with the GROUP BY clause. This means that the query will calculate the sum of salaries for each combination of dept_id and join_date. It adheres to the SQL rule that every item in the SELECT list must be either an aggregate function or appear in the GROUP BY clause.
Option B is invalid due to a typo in SELECT depe_id and also because it ends with a colon rather than a semicolon.
Option C is invalid because you cannot nest aggregate functions like MAX(AVG(salary)) without a subquery.
Option D is invalid for the same reason as option C, where it tries to nest aggregate functions AVG(MAX(salary)), which is not allowed directly in SQL without a subquery.
For further reference, you can consult the Oracle 12c documentation, which provides comprehensive guidelines on how to use the GROUP BY clause and aggregate functions like SUM():
Oracle Database SQL Language Reference, 12c Release 1 (12.1): GROUP BY Clause
Oracle Database SQL Language Reference, 12c Release 1 (12.1): Aggregate Functions
The PRODUCT_INFORMATION table has a UNIT_PRICE column of data type NUMBER(8, 2).
Evaluate this SQL statement:
SELECT TO_CHAR(unit_price,'$9,999') FROM PRODUCT_INFORMATION;
Which two statements are true about the output?
A row whose UNIT_PRICE column contains the value 1023.99 will be displayed as $1,024.
A row whose UNIT_PRICE column contains the value 1023.99 will be displayed as $1,023.
A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as $1,0236.
A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as $1,023.
A row whose UNIT_PRICE column contains the value 10235.99 will be displayed as #####
The TO_CHAR function is used to convert a number to a string format in Oracle SQL. In this format mask '$9,999', the dollar sign is a literal, and the 9 placeholders represent a digit in the output. The comma is a digit group separator.
A. This statement is incorrect because the format model does not have enough digit placeholders to display the full number 1023.99; it would round it to $1,023 not $1,024. B. This statement is correct. Given the format '$9,999', the number 1023.99 will be formatted as $1,023 because the format rounds the number to no decimal places. C. This is incorrect because the format '$9,999' cannot display the number 10235.99; it exceeds the format's capacity. D. This is incorrect for the same reason as C, and the format would not change the thousands to hundreds. E. This statement is correct. If the number exceeds the maximum length of the format mask, which is 4 digits in this case, Oracle SQL displays a series of hash marks (#) instead of the number.
These formatting rules are described in the Oracle Database SQL Language Reference, which covers the TO_CHAR function and its number formatting capabilities.
Which two are true about self joins?
They are always equijoins.
They require the NOT EXISTS operator in the join condition.
They have no join condition.
They can use INNER JOIN and LEFT JOIN.
They require table aliases.
They require the EXISTS opnrator in the join condition.
Self joins in Oracle Database 12c SQL have these characteristics:
Option D: They can use INNER JOIN and LEFT JOIN.
Self joins can indeed use various join types, including inner and left outer joins. A self join is a regular join, but the table is joined with itself.
Option E: They require table aliases.
When a table is joined to itself, aliases are required to distinguish between the different instances of the same table within the same query.
Options A, B, C, and F are incorrect:
Option A is incorrect because self joins can be non-equijoins as well.
Option B is incorrect because self joins do not require the NOT EXISTS operator. They may require a condition, but NOT EXISTS is not a necessity.
Option C is incorrect because a join condition is needed to relate the two instances of the same table in a self join.
Option F is incorrect for the same reason as B; the EXISTS operator is not a requirement for self joins.
Which three statements about roles are true?
Roles are assigned to roles using the ALTER ROLE Statement
A role is a named group of related privileges that can only be assigned to a user
Roles are assigned to users using the ALTER USER statement
A single role can be assigned to multiple users.
A single user can be assigned multiple roles
Privileges are assigned to a role using the ALTER ROLE statement.
Privileges are assigned to a role using the GRANT statement.
Roles are named collections of privileges in Oracle databases.
A. False. Roles cannot be assigned to other roles using the ALTER ROLE statement.
B. False. Roles can be assigned to both users and other roles.
C. True. Roles are assigned to users using the ALTER USER statement, but this is not the only method.
D. True. A single role can be assigned to multiple users, simplifying the management of user privileges.
E. True. A single user can be assigned multiple roles.
F. False. Privileges are not assigned to a role using the ALTER ROLE statement.
G. True. Privileges are assigned to a role using the GRANT statement.
The ORDERS table has a primary key constraint on the ORDER_ID column.
The ORDER_ITEMS table has a foreign key constraint on the ORDER_ID column, referencing the primary key of the ORDERS table.
The constraint is defined with on DELETE CASCADE.
There are rows in the ORDERS table with an ORDER_TOTAL less than 1000.
Which three DELETE statements execute successfully?
DELETE FROM orders WHERE order_total<1000;
DELETE * FROM orders WHERE order_total<1000;
DELETE orders WHERE order_total<1000;
DELETE FROM orders;
DELETE order_id FROM orders WHERE order_total<1000;
In Oracle 12c SQL, the DELETE statement is used to remove rows from a table based on a condition. Given the constraints and the information provided, let's evaluate the options:
A. DELETE FROM orders WHERE order_total<1000;: This statement is correctly formatted and will delete rows from the ORDERS table where ORDER_TOTAL is less than 1000. If there is a DELETE CASCADE constraint, corresponding rows in the ORDER_ITEMS table will also be deleted.
B. DELETE * FROM orders WHERE order_total<1000;: This syntax is incorrect. The asterisk (*) is not used in the DELETE statement.
C. DELETE orders WHERE order_total<1000;: This statement is also correctly formatted and is a shorthand version of the DELETE statement without the FROM clause.
D. DELETE FROM orders;: This statement will delete all rows from the ORDERS table, and with DELETE CASCADE, it will also delete all related rows in the ORDER_ITEMS table.
E. DELETE order_id FROM orders WHERE order_total<1000;: This syntax is incorrect because you cannot specify a column after the DELETE keyword.
References:
Oracle Database SQL Language Reference 12c Release 1 (12.1), DELETE Statement
SELECT *
FROM bricks,colors;
Which two statements are true?
You can add an ON clause with a join condition.
You can add a WHERE clause with filtering criteria.
It returns the number of rows in BRICKS plus the number of rows in COLORS.
You can add a USING clause with a join condition.
It returnsthe same rows as SELECT * FROM bricks CROSS JOIN colors.
For the SELECT statement from two tables without a JOIN clause:
Option B: You can add a WHERE clause with filtering criteria.
A WHERE clause can be added to a query to filter the results based on specified conditions.
Option E: It returns the same rows as SELECT * FROM bricks CROSS JOIN colors.
A comma-separated list of tables in a FROM clause is equivalent to a CROSS JOIN, resulting in a Cartesian product of the tables.
Options A, C, and D are incorrect because:
Option A: You cannot add an ON clause without changing the comma-separated FROM clause to a proper JOIN.
Option C: It returns the Cartesian product, not the sum, of the rows from BRICKS and COLORS.
Option D: A USING clause is not applicable without changing the syntax to a proper JOIN.
You issued this command: DROP TABLE hr. employees;
Which three statements are true?
ALL constraints defined on HR, EMPLOYEES are dropped.
The HR. EMPLOYEES table may be moved to the recycle bin.
Synonyms for HR EMPLOYEES are dropped.
Sequences used to populate columns in the HR. EMPLOYEES table are dropped.
All indexes defined on HR, EMPLOYEES are dropped.
Views referencing HR, EMPLOYEES are dropped.
Regarding the DROP TABLE command:
A. ALL constraints defined on HR.EMPLOYEES are dropped: Dropping a table will automatically drop all constraints associated with that table.
B. The HR.EMPLOYEES table may be moved to the recycle bin: In Oracle, unless explicitly using PURGE, dropped tables go to the recycle bin, allowing recovery.
E. All indexes defined on HR, EMPLOYEES are dropped: When a table is dropped, all its indexes are also automatically dropped.
Incorrect options:
C: Synonyms are not automatically dropped when the table is dropped; they become invalid.
D: Sequences are independent objects and are not dropped when a table is dropped.
F: Views are not dropped; however, they will return errors upon being queried if their base table is dropped.
Which three queries execute successfully?
SELECT (SYSDATE-DATE '2019-01-01') / 1 FROM DUAL;
SELECT 1 / SYSDATE - DATE '2019-01-01' FROM DUAL;
SELECT SYSDATE / DATE '2019-01-01' - 1 FROM DUAL
SELECT SYSDATE - DATE '2019-01-01' - 1 FROM DUAL;
SELECT 1 – SYSDATE- DATE '2019-01-01' FROM DUAL;
SELECT SYSDATE - 1 - DATE'2019-01-01' EROM DUAL;
In Oracle SQL, date arithmetic can be performed directly, subtracting one date from another to get the number of days between them:
Option A:
SELECT (SYSDATE - DATE '2019-01-01') / 1 FROM DUAL; This query successfully calculates the difference between the current date and a specific date.
Option D:
SELECT SYSDATE - DATE '2019-01-01' - 1 FROM DUAL; This query subtracts a specific date from the current date and then subtracts 1 more day, which will execute successfully.
Option F:
SELECT SYSDATE - 1 - DATE '2019-01-01' FROM DUAL; Similar to D, this will successfully compute the date difference minus one day.
Options B, C, and E are incorrect because:
Option B and Option C: You cannot divide by a date or divide a date by a number.
Option E: You cannot subtract a date from a number.
Which three statements are true about built-in data types?
A VARCHAR2 blank-pads column values only if the data stored is non-numeric and contains no special characters.
The default length for a CHAR column is always one character.
A VARCHAR2 column definition does not require the length to be specified.
A BLOB stores unstructured binary data within the database.
A CHAR column definition does not require the length to be specified.
A BFILE stores unstructured binary data in operating system files.
D: True. A BLOB (Binary Large Object) is used to store unstructured binary data within the Oracle Database. It can hold a variable amount of data.
F: True. A BFILE is a datatype in Oracle SQL used to store a locator (pointer) that points to binary data stored in operating system files outside of the Oracle Database.
Both BLOB and BFILE are used for large binary data but differ in where the data is actually stored - BLOB stores the data inside the Oracle Database, whereas BFILE stores the data in the file system outside the database.
References:The Oracle Database SQL Language Reference guide details the characteristics and uses of BLOB and BFILE datatypes among others, describing their storage characteristics and data type definitions.
Which two statements are true about a full outer join?
It includes rows that are returned by an inner join.
The Oracle join operator (+) must be used on both sides of the join condition in the WHERE clause.
It includes rows that are returned by a Cartesian product.
It returns matched and unmatched rows from both tables being joined.
It returns only unmatched rows from both tables being joined.
In Oracle Database 12c, regarding a full outer join:
A. It includes rows that are returned by an inner join. This is true. A full outer join includes all rows from both joined tables, matching wherever possible. When there's a match in both tables (as with an inner join), these rows are included.
D. It returns matched and unmatched rows from both tables being joined. This is correct and the essence of a full outer join. It combines the results of both left and right outer joins, showing all rows from both tables with matching rows from the opposite table where available.
Options B, C, and E are incorrect:
B is incorrect because the Oracle join operator (+) is used for syntax in older versions and cannot implement a full outer join by using (+) on both sides. Proper syntax uses the FULL OUTER JOIN keyword.
C is incorrect as a Cartesian product is the result of a cross join, not a full outer join.
E is incorrect because it only describes the scenario of a full anti-join, not a full outer join.
Examine this business rule:
Each student can work on multiple projects and each project can have multiple students.
You must design an Entity Relationship(ER) model for optimal data storage and allow for generating reports in this format:
Which two statements are true?
An associative table must be created with a composite key of STUDENT_ID and PROJRCT_ID, which is the foreign key linked to the STUDENTS and PROJECTS entities.
PROJECT_ID must be the primary key in the PROJECTS entity and foreign key in the STUDENTS entity.
The ER must have a 1-to-many relationship between the STUDENTS and PROJECTS entities.
The ER must have a many to-many relationship between the STUDENTS and PROJECTS entities that must be resolved into 1-to-many relationships.
STUDENT ID must be the primary key in the STUDENTS entity and foreign key in the PROJECTS entity.
Based on the business rule, the true statements regarding the Entity Relationship (ER) model are:
A. An associative table must be created with a composite key of STUDENT_ID and PROJECT_ID, which is the foreign key linked to the STUDENTS and PROJECTS entities. This is true because, in a many-to-many relationship, an associative (junction) table is used to maintain the associations between two entities.
D. The ER must have a many-to-many relationship between the STUDENTS and PROJECTS entities that must be resolved into 1-to-many relationships. This is correct because many-to-many relationships are resolved by introducing an associative table that breaks it down into two 1-to-many relationships.
Options B, C, and E are incorrect:
B is incorrect because PROJECT_ID should not be a foreign key in the STUDENTS entity in a many-to-many relationship.
C is incorrect as the rule indicates a many-to-many relationship, not 1-to-many.
E is incorrect because STUDENT_ID should not be a foreign key in the PROJECTS entity in a many-to-many relationship.
Examine the description of the EMPLOYEES table:

Which two statements will run successfully?
SELECT 'The first_name is '' || first_name || '' FROM employees ;
SELECT 'The first_name is '''||first_name ||'''' FROM employees ;
SELECT 'The first_name is ''' ||first_name||''' FROM employees ;
SELECT 'The first_name is '|| first_name|| '' FROM employees;
SELECT 'The first_name is \'' || first_name || '\'' FROM employees;
In Oracle SQL, to include single quotes in a string literal, you need to use two single-quote characters.
A. This statement will not run successfully because the single quotes are not properly escaped. After the text The first_name is , there should be two single quotes to start the string literal for the first name.
B. This statement will run successfully. It properly escapes the single quotes by using two single quotes around first_name. This will result in the output like The first_name is 'John'.
C. This statement will run successfully as well. The two single quotes after The first_name is and before FROM employees are correctly used to delimit the first name.
D. This statement will not run successfully. There is a missing single quote before the double pipe (||) operator, and at the end of the statement, only one single quote is used instead of two for escaping.
E. This statement will not run successfully because the backslash is not used to escape single quotes in Oracle SQL. The proper method is to use two single quotes without a backslash.
References:
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "Text Literals"
Oracle Database SQL Language Reference, 12c Release 1 (12.1): "String Concatenation Operator"
Which statement is true about TRUNCATE and DELETE?
For large tables TRUNCATE is faster than DELETE.
For tables with multiple indexes and triggers is faster than TRUNCATE.
You can never TRUNCATE a table if foreign key constraints will be violated.
You can never tows from a table if foreign key constraints will be violated.
A: True. TRUNCATE is generally faster than DELETE for removing all rows from a table because TRUNCATE is a DDL (Data Definition Language) operation that minimally logs the action and does not generate rollback information. TRUNCATE drops and re-creates the table, which is much quicker than deleting rows one by one as DELETE does, especially for large tables. Also, TRUNCATE does not fire triggers.
References:
Oracle documentation specifies that TRUNCATE is faster because it doesn't generate redo logs for each row as DELETE would.
TRUNCATE cannot be rolled back once executed, since it is a DDL command and does not generate rollback information as DML commands do.
Which statement falls to execute successfully?
SELECT *
FROM employees e
JOIN department d
WHERE e.department_id=d.department_id
AND d.department_id=90;
SELECT *
FROM employees e
JOIN departments d
ON e.department_id=d.department_id
WHERE d.department_id=90;
SELECT *
FROM employees e
JOIN departments d
ON e.department_id=d.department_id
AND d.department_id=90;
SELECT *
FROM employees e
JOIN departments d
ON d.departments_id=90
WHERE e.department_id=d.department_id;
Given the statements, the failure to execute would be due to improper SQL syntax or logical structuring of the JOIN clause:
A. SELECT * FROM employees e JOIN department d WHERE e.department_id=d.department_id AND d.department_id=90: This statement will fail because it incorrectly uses the JOIN syntax without an ON clause, which is necessary to specify the condition on which the tables are joined. This statement mistakenly places the join condition in the WHERE clause without using ON.
Correct options (executes successfully):
B: Correctly formulated JOIN with ON and an additional condition in the WHERE clause.
C: Incorporates the filtering directly in the ON clause, which is a valid method to restrict the rows returned by the JOIN based on conditions related to both tables.
D: Although it appears awkward due to the order of conditions in the ON clause, it is syntactically correct.
These answers reflect typical use and constraints in SQL queries and are aligned with Oracle Database 12c standards for SQL syntax and operations.
Examine the data in the CUST NAME column of the CUSTOMERS table:
CUST_NAME
------------------------------
Renske Ladwig
Jason Mallin
Samuel McCain
Allan MCEwen
Irene Mikkilineni
Julia Nayer
You want to display the CUST_NAME values where the last name starts with Mc or MC. Which two WHERE clauses give the required result?
WHERE INITCAP (SUBSTR(cust_name, INSTR(cust_name,'') +1)) IN ('MC%','Mc%)
WHERE UPPER (SUBSTR(cust_name, INSTR(cust_name, '') +1)) LIKE UPPER('MC%')
WHERE INITCAP(SUBSTR(cust_name, INSTR(cust_name,'') +1)) LIKE'Mc%'
WHERE SUBSTR(cust_name,INSTR(cust_name,'') +1) LIKE'Mc%' OR'MC%'
WHERE SUBSTR(cust_name, INSTR(cust_name,'') +1) LIKE'Mc%'
To find customers whose last names start with "Mc" or "MC", we need to ensure our SQL query correctly identifies and compares these prefixes regardless of case variations. Let's analyze the given options:
Option B: WHERE UPPER(SUBSTR(cust_name, INSTR(cust_name, ' ') + 1)) LIKE UPPER('MC%')This clause uses UPPER to convert both the extracted substring (starting just after the first space, assuming it indicates the start of the last name) and the comparison string 'MC%' to uppercase. This ensures case-insensitive comparison. The LIKE operator is used to match any last names starting with "MC", which will correctly capture both "Mc" and "MC". This option is correct.
Option C: WHERE INITCAP(SUBSTR(cust_name, INSTR(cust_name, ' ') + 1)) LIKE 'Mc%'This clause applies INITCAP to the substring, which capitalizes the first letter of each word and makes other letters lowercase. The result is compared to 'Mc%', assuming only the last name follows the space. This approach will match last names starting with "Mc" (like "McEwen"), but not "MC". However, considering we're looking for "Mc" specifically, this clause works under the assumption that "Mc" is treated as proper capitalization for these last names. Thus, it can also be considered correct, albeit less inclusive than option B.
The other options either use incorrect syntax or apply case-sensitive matches without ensuring that both "Mc" and "MC" are captured:
Option A: Contains syntax errors (unmatched quotes and wrong use of IN).
Option D: Uses case-sensitive match without combining both "Mc" and "MC".
Option E: Only matches "Mc", which is too specific.
Which three actions can you perform on an existing table containing date?
Add a new column as the table's first column.
Define a default value that is automatically inserted into a column containing nulls.
Add a new NOT NULL Column with a DEFAULT value.
Change a DATE Column containing data to a NUMBER data type.
Increase the width of a numeric column.
Change the default value of a column.
C: True. You can add a new NOT NULL column to an existing table, provided you specify a DEFAULT value for the column. This ensures that existing rows in the table can be updated with a default value, thus maintaining the NOT NULL constraint integrity.
E: True. It is permissible to increase the width of a numeric column, provided the change does not truncate existing data. This change is generally safe as it allows for greater values or more precision without affecting existing data.
F: True. The default value of a column can be changed. This action affects subsequent insert operations but does not alter the values of existing rows. Changing the default is useful for adapting tables to evolving business rules without impacting existing data.
Which three items does a direction of a relationship contain?
an attribute
a cardinality
label
an optionality
a unique identifier
an entity
In data modeling and database design, the direction of a relationship typically includes:
Option B: a cardinality
Cardinality refers to the numerical relationships between two entities, indicating the number of instances of one entity that can or must be associated with each instance of another.
Option C: label
A label is often used to describe the role or purpose of the relationship in a way that clarifies the nature of the interaction between entities.
Option D: an optionality
Optionality indicates whether or not a relationship is mandatory or optional; in other words, it shows if an instance of an entity must be related to an instance of another entity or if it can exist without such a relationship.
Options A, E, and F are not part of the direction of a relationship:
Option A: An attribute is a property or characteristic of an entity, not the direction of a relationship.
Option E: A unique identifier uniquely identifies each instance of an entity, not a relationship's direction.
Option F: An entity is a thing with distinct and independent existence in a database, usually mapped to a table, not a part of the direction of a relationship.
Whith three statements are true about built in data types?
A VARCHAR2 blank pads column values only if the data stored is non numeric and contains no special characlers
A BFILE stores unstructured binary data in operating systerm files
A CHAR column definition does not require the length to be specified
The default length for a CHAR column is always one character
A VARCHAR2 column definition does not require the length to be specified
A BLOB stores unstructured binary data within the database
The true statements about built-in data types in Oracle are:
B: A BFILE is a data type in Oracle that allows for a read-only link to binary files stored outside the database in the operating system. This is correct as per Oracle's documentation.
D: The default length for a CHAR column, when not specified, is one character. This is according to the Oracle SQL standard.
F: A BLOB is used for storing binary data within the Oracle database, allowing for storage of large amounts of unstructured binary data.
The incorrect options are:
A: A VARCHAR2 column does not blank-pad values; it is CHAR that may blank-pad to the fixed length.
C: A CHAR column requires a length specification, although if omitted, the default is one character.
E: A VARCHAR2 column requires a length specification; without it, the statement will fail.
References:
Oracle Documentation on Data Types: Data Types
Oracle Documentation on LOBs: LOBs
Oracle Documentation on Character Data Types: Character Data Types
Examine the description of the EMPLOYEES table:

Which two queries return rows for employees whose manager works in a different department?
SELECT emp. *
FROM employees emp
WHERE manager_ id NOT IN (
SELECT mgr.employee_ id
FROM employees mgr
WHERE emp. department_ id < > mgr.department_ id
);
SELECT emp.*
FROM employees emp
WHERE NOT EXISTS (
SELECT NULL
FROM employees mgr
WHERE emp.manager id = mgr.employee_ id
AND emp.department_id<>mgr.department_id
);
SELECT emp.*
FROM employees emp
LEFT JOIN employees mgr
ON emp.manager_ id = mgr.employee_ id
AND emp. department id < > mgr. department_ id;
SELECT emp. *
FROM employees emp
RIGHT JOIN employees mgr
ON emp.manager_ id = mgr. employee id
AND emp. department id <> mgr.department_ id
WHERE emp. employee_ id IS NOT NULL;
SELECT emp. *
FROM employees emp
JOIN employees mgr
ON emp. manager_ id = mgr. employee_ id
AND emp. department_ id<> mgr.department_ id;
To find employees whose manager works in a different department, you can use a subquery or a join that compares the DEPARTMENT_ID of the employee with the DEPARTMENT_ID of their manager.
A. This query is incorrect because the NOT IN subquery incorrectly attempts to compare EMPLOYEE_ID with MANAGER_ID, and the correlation condition inside the subquery is incorrect.
B. This query is correct. The NOT EXISTS clause correctly identifies employees whose MANAGER_ID matches the EMPLOYEE_ID of another employee (mgr) and where the DEPARTMENT_ID differs from that manager's DEPARTMENT_ID.
C. This query is incorrect because the LEFT JOIN will return all employees, and there is no WHERE clause to filter out those employees whose managers are in the same department.
D. This query is incorrect. The RIGHT JOIN does not ensure that the resulting rows are for employees whose manager works in a different department. It also returns all managers, which is not the requirement.
E. This query is correct. The JOIN ensures that the returned rows are for employees (emp) whose MANAGER_ID matches the EMPLOYEE_ID of managers (mgr), and it correctly filters to include only those employees whose DEPARTMENT_ID is different from their manager's DEPARTMENT_ID.
Which two are true about the data dictionary?
Base tables in the data dictionary have the prefix DBA_.
All user actions are recorded in the data dictionary.
The data dictionary is constantly updated to reflect changes to database objects, permissions, and data.
All users have permissions to access all information in the data dictionary by default
The SYS user owns all base tables and user-accessible views in the data dictionary.
C. True, the data dictionary is constantly updated to reflect changes to the metadata of the database objects, permissions, and structures, among other things.E. True, the SYS user owns all base tables in the data dictionary. These base tables underlie all data dictionary views that are accessible by the users.
A, B, and D are not correct because: A. Base tables do not necessarily have the prefix DBA_; instead, DBA_ is a prefix for administrative views that are accessible to users with DBA privileges. B. The data dictionary records metadata about the actions, not the actions themselves. D. Not all users have access to all information in the data dictionary. Access is controlled by privileges.
References:
Oracle documentation on data dictionary and dynamic performance views: Oracle Database Reference
Understanding the Oracle data dictionary: Oracle Database Concepts
Which statement is true regarding the SESSION_PRIVS dictionary view?
It contains the object privileges granted to other users by the current user session.
It contains the system privileges granted to other users by the current User session.
It contains the current system privileges available in the user session.
It contains the current object privileges available in the user session.
Regarding the SESSION_PRIVS dictionary view:
C. It contains the current system privileges available in the user session: This view displays the system privileges granted to the current user, making it a tool for understanding which actions the user is allowed to perform in the current session.
Incorrect options:
A and B: SESSION_PRIVS does not contain information about privileges granted to or by other users; it specifically lists the privileges available to the current session.
D: It does not contain object privileges; these are contained in other views such as USER_TAB_PRIVS.
You must find the number of employees whose salary is lower than employee 110.
Which statement fails to do this?
SELECT COUNT (*)
FROM employees
JOIN employees a
ON e. salary< a. salary
WHERE a. employee_ id= 110;
SELECT COUNT (* )
FROM employees
WHERE salary < (SELECT salary FROM employees WHERE employee 业id =
110) ;
SELECT COUNT (*)
FROM employees e
JOIN (SELECT salary FROM employees WHERE employee_ id= 110) a
ON e. salary< a. salary;
SELECT COUNT (* )
FROM employees e
WHERE e. salary < (SELECT a. salary FROM employees a WHERE e. employee_ id = 110);
In this context, the correct answers will provide a count of employees with a salary less than that of employee with ID 110. Let's evaluate the provided statements:
A: This statement is incorrect due to a syntax error; it uses alias 'e' without defining it, and 'a' is also used incorrectly in the JOIN clause. It should have been written with proper aliases.
B: This statement is correct as it uses a subquery to find the salary of employee ID 110 and compares it to the salaries of all employees to get the count.
C: This statement is also correct as it creates a derived table with the salary of employee ID 110 and compares it with the salaries of the 'employees' table using a JOIN.
D: This is the statement that fails. It is incorrect because the subquery references 'e.employee_id = 110', which will compare the salary of each employee to themselves if their ID is 110, not to the salary of employee 110 for all employees.
Which is the default column or columns for sorting output from compound queries using SET operators such as INTERSECT in a SQL statement?
The first column in the last SELECT of the compound query
The first NUMBER column in the first SELECT of the compound query
The first VARCHAR2 column in the first SELECT of the compound query
The first column in the first SELECT of the compound query
The first NUMBER or VARCHAR2 column in the last SELECTof the compound query
For the sorting of output in compound queries (INTERSECT, UNION, etc.):
D. The first column in the first SELECT of the compound query: By default, Oracle does not automatically sort the results of SET operations unless an ORDER BY clause is explicitly stated. However, if an ORDER BY is implied or specified without explicit columns, the default sorting would logically involve the first column specified in the first SELECT statement of the compound query.
Examine these two queries and their output:
SELECT deptno, dname FROM dept;

SELECT ename, job, deptno FROM emp ORDER BY deptno;

Now examine this query:
SELECT ename, dname
FROM emp CROSS JOIN dept WHERE job = 'MANAGER'
AND dept.deptno IN (10, 20) ;
64
6
3
12
In a CROSS JOIN (also known as a Cartesian join), each row from the first table (emp) is joined to every row of the second table (dept). When we apply the filter for job = 'MANAGER' and dept.deptno IN (10, 20), we are restricting the results to managers in departments 10 and 20.
From the given data:
There are 2 managers in department 10 (CLARK and KING).
There is 1 manager in department 20 (JONES).
With a cross join, each of these emp records will join with each dept record where deptno is 10 or 20. Since there are two departments (10 and 20) in the dept table, each employee will match with two departments.
Therefore, the result set will be:
CLARK with accounting (dept 10) and research (dept 20)
KING with accounting (dept 10) and research (dept 20)
JONES with accounting (dept 10) and research (dept 20)
That gives us a total of 6 rows, which means the correct answer is B: 6.
Examine this query:
SELECT TRUNC (ROUND(156.00,-2),-1) FROM DUAL; What is the result?
16
160
150
200
100
The query uses two functions: ROUND and TRUNC. The ROUND function will round the number 156.00 to the nearest hundred because of the -2 which specifies the number of decimal places to round to. This will result in 200. Then the TRUNC function truncates this number to the nearest 10, due to the -1 argument, which will give us 200 as the result since truncation does not change the rounded value in this case.
A. 16 (Incorrect)
B. 160 (Incorrect)
C. 150 (Incorrect)
D. 200 (Incorrect)
E. 100 (Incorrect)
Which two statements are true about the COUNT function?
It can only be used for NUMBER data types.
COUNT (DISTINCT inv_amt) returns the number of rows excluding rows containing duplicates and NULLs in the INV_AMT column
COUNT(*) returns the number of rows in a table including duplicate rows and rows containing NULLs in any column.
A SELECT statement using the COUNT function with a DISTINCT keyword cannot have a WHERE clause.
COUNT(inv_amt) returns the number of rows in a table including rows with NULL in the INV_AMT column.
The COUNT function is one of the most commonly used aggregate functions in SQL for determining the number of items in a group. Here's why the correct answers are B and C:
A: Incorrect. COUNT can be used with any data type, not just NUMBER. It counts rows without regard to data type.
B: Correct. COUNT(DISTINCT inv_amt) counts the number of unique non-null values in the column inv_amt. It excludes duplicates and ignores NULL values.
C: Correct. COUNT(*) counts all rows in a table, including those with duplicates and those with NULLs in any column. It is a total row count regardless of content.
D: Incorrect. You can use a WHERE clause with COUNT. The WHERE clause filters rows before counting, which is standard in SQL.
E: Incorrect. COUNT(inv_amt) counts the rows where inv_amt is not NULL. Rows with NULL in the inv_amt column are not counted.
Examine the command to create the BOOKS table.
SQL> create table books(book id CHAR(6) PRIMARY KEY,
title VARCHAR2(100) NOT NULL,
publisher_id VARCHAR2(4),
author_id VARCHAR2 (50));
The BOOK ID value 101 does not exist in the table.
Examine the SQL statement.
insert into books (book id title, author_id values
(‘101’,’LEARNING SQL’,’Tim Jones’)
It executes successfully and the row is inserted with a null PLBLISHER_ID.
It executes successfully only if NULL is explicitly specified in the INSERT statement.
It executes successfully only NULL PUBLISHER_ID column name is added to the columns list in the INSERT statement.
It executes successfully onlyif NULL PUBLISHER ID column name is added to the columns list and NULL is explicitly specified In the INSERT statement.
A. It executes successfully and the row is inserted with a null PUBLISHER_ID: The SQL statement does not specify the publisher_id, and since there is no NOT NULL constraint on this column, Oracle will insert the row with a NULL value for publisher_id. The statement is syntactically correct, assuming the column names and values are properly specified and formatted.
Which three are true about privileges and roles?
A role is owned by the user who created it.
System privileges always set privileges for an entire database.
All roles are owned by the SYS schema.
A role can contain a combination of several privileges and roles.
A user has all object privileges for every object in their schema by default.
PUBLIC can be revoked from a user.
PUBLIC acts as a default role granted to every user in a database
Roles and privileges in Oracle manage access and capabilities within the database:
Option A: False. Roles are not "owned" in the traditional sense by the user who created them. They exist independently within the Oracle database and are assigned to users.
Option B: False. System privileges can be very granular, affecting specific types of operations or database objects, not always the entire database.
Option C: False. Roles are not owned by the SYS schema but are managed by database security and can be created by any user with sufficient privileges.
Option D: True. A role can indeed contain a combination of several privileges, including other roles, allowing for flexible and layered security configurations.
Option E: True. By default, a user has all object privileges for objects they own (i.e., objects in their schema).
Option F: False. PUBLIC is a special designation that applies to all users; individual privileges granted to PUBLIC cannot be revoked from a single user without revoking them from all users.
Option G: True. PUBLIC is a role granted by default to every user in an Oracle database, providing basic privileges necessary for general usability of the database.
MANAGER is an existing role with no privileges or roles.
EMP is an existing role containing the CREATE TABLE privilege.
EMPLOYEES is an existing table in the HR schema.
Which two commands execute successfully?
GRANT CREATE SEQUENCE TO manager, emp;
GRANT SELECT, INSERT ON hr.employees TO manager WITH GRANT OPTION:
GRANT CREATE TABLE, emp TO manager;
GRANT CREATE TABLE, SELECT ON hr. employees TO manager;
GRANT CREATE ANY SESSION, CREATE ANY TABLE TO manager;
In Oracle SQL, roles can be granted privileges and other roles, and these privileges can then be passed on to users.
Statement A is correct: GRANT CREATE SEQUENCE TO manager, emp; successfully grants the CREATE SEQUENCE privilege to both the manager and emp roles.
Statement E is correct: GRANT CREATE ANY SESSION, CREATE ANY TABLE TO manager; successfully grants two system privileges to the manager role.
Statements B, C, and D are incorrect for the following reasons:
B is incorrect because the correct syntax to grant object privileges includes separating privileges with commas, not spaces, and the object name should be in singular form (hr.employees).
C is incorrect because you cannot grant a role and a privilege in the same statement.
D is incorrect because the correct syntax for granting object privileges does not include the privilege CREATE TABLE before specifying the object (hr.employees).
Which two statements are true about the ORDER BY clause?
Numeric values are displayed in descending order if they have decimal positions.
Only columns that are specified in the SELECT list can be used in the ORDER BY clause.
In a character sort, the values are case-sensitive.
Column aliases can be used in the ORDER BY clause.
NULLS are not included in the sort operation.
C: True. In Oracle Database 12c, character sorts are case-sensitive by default, meaning that it differentiates between uppercase and lowercase letters when sorting data. This behavior aligns with the binary collation rules typically used, unless explicitly overridden by using different collation settings.
D: True. Column aliases can indeed be used in the ORDER BY clause in Oracle SQL. This allows for more readable and maintainable code, as you can define a column alias in the SELECT list and refer to that alias in the ORDER BY clause. This usage promotes clarity, especially when dealing with complex calculations or function applications in the select list.
Which two actions can you perform with object privileges?
Create roles.
Delete rows from tables in any schema except sys.
Set default and temporary tablespaces for a user.
Create FOREIGN KEY constraints that reference tables in other schemas.
Execute a procedure or function in another schema.
Regarding object privileges in an Oracle database:
B. Delete rows from tables in any schema except sys: Object privileges include DELETE on tables, which can be granted by the owner of the table or a user with adequate privileges, excluding system schemas like SYS due to their critical role.
E. Execute a procedure or function in another schema: EXECUTE is a specific object privilege that can be granted on procedures and functions, allowing users to run these objects in schemas other than their own.
Incorrect options:
A: Creation of roles is related to system privileges, not object privileges.
C: Setting default and temporary tablespaces for a user involves system-level operations, not object-level privileges.
D: Creation of foreign key constraints involves referencing rights, which, while related, are not directly granted through object privileges but need appropriate REFERENCES permission.
What is true about non-equijoin statement performance?
The between condition always performs less well than using the >= and <= conditions.
The Oracle join syntax performs better than the SQL: 1999 compliant ANSI join syntax.
The join syntax used makes no difference to performance.
The between condition always performs better than using the >= and <= conditions.
Table aliases can improve performance.
When comparing the performance of different SQL join types and conditions, Oracle SQL optimizations generally ensure that performance is consistent across different syntactical forms of expressing the same logic:
Option A: False. The BETWEEN condition does not inherently perform worse than using >= and <=. Oracle's optimizer typically evaluates these conditions similarly, optimizing the underlying execution based on the data distribution and available indexes.
Option B: False. Oracle's optimizer is designed to handle both Oracle-specific join syntax and ANSI join syntax with equal competence. Performance differences would typically be negligible because the optimizer translates both into an optimal execution plan based on the same underlying mechanisms.
Option C: True. The join syntax used (whether Oracle's traditional syntax or ANSI standard syntax) generally does not affect the performance. Oracle's query optimizer is adept at translating different syntaxes into efficient execution plans.
Option D: False. The assertion that BETWEEN always performs better than >= and <= is incorrect. Performance depends more on factors like indexing, the specific data and distribution, and the Oracle optimizer's capabilities than on the mere choice of syntax.
Option E: False. While table aliases help improve query readability and can prevent ambiguity in SQL queries, they do not inherently improve performance. Their use is a best practice for code clarity and maintenance, not performance enhancement.
You execute this command:
TRUNCATE TABLE depts;
Which two are true?
It retains the indexes defined on the table.
It drops any triggers defined on the table.
A Flashback TABLE statement can be used to retrieve the deleted data.
It retains the integrity constraints defined on the table.
A ROLLBACK statement can be used to retrieve the deleted data.
It always retains the space used by the removed rows
The TRUNCATE TABLE command in Oracle SQL is used to quickly delete all rows from a table:
Option A:
It retains the indexes defined on the table. TRUNCATE does not affect the structure of the table, including its indexes.
Option D:
It retains the integrity constraints defined on the table. TRUNCATE does not remove or disable integrity constraints, except for unenforced foreign keys.
Options B, C, E, and F are incorrect because:
Option B: TRUNCATE does not drop triggers; it only removes all rows.
Option C: Flashback Table cannot be used after a TRUNCATE because TRUNCATE is a DDL operation that does not generate undo data for flashback.
Option E: A ROLLBACK cannot be used after a TRUNCATE because TRUNCATE is a DDL command that implicitly commits.
Option F: TRUNCATE may deallocate the space used by the table, depending on the database version and specific options used with the TRUNCATE command.
Copyright © 2014-2025 Examstrust. All Rights Reserved