What is the MINIMUM size requirement when creating a Snowpark-optimized virtual warehouse?
X-Small
Small
Medium
Large
When creating a Snowpark-optimized virtual warehouse in Snowflake, the minimum size requirement is Small. Snowpark is designed to handle data processing workloads efficiently, and the Small size ensures adequate resources for such tasks.
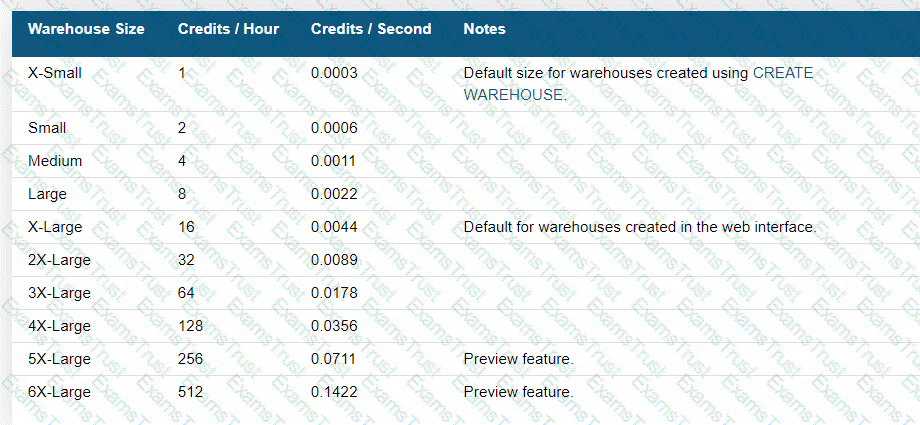
Virtual Warehouse Sizes:
Snowflake offers different sizes for virtual warehouses, ranging from X-Small to 6X-Large.
Each size corresponds to a specific level of compute resources.
Minimum Size Requirement for Snowpark:
A Small virtual warehouse is the minimum size required to optimize performance and resource allocation for Snowpark workloads.
This ensures that the warehouse has sufficient capacity to handle data processing and transformation tasks efficiently.
References:
Snowflake Documentation: Virtual Warehouse Sizes
Which command can be used to list all network policies available in an account?
DESCRIBE SESSION POLICY
DESCRIBE NETWORK POLICY
SHOW SESSION POLICIES
SHOW NETWORK POLICIES
To list all network policies available in an account, the correct command is SHOW NETWORK POLICIES. Network policies in Snowflake are used to define and enforce rules for how users can connect to Snowflake, including IP whitelisting and other connection requirements. The SHOW NETWORK POLICIES command provides a list of all network policies defined within the account, along with their details.
The DESCRIBE SESSION POLICY and DESCRIBE NETWORK POLICY commands do not exist in Snowflake SQL syntax. The SHOW SESSION POLICIES command is also incorrect, as it does not pertain to the correct naming convention used by Snowflake for network policy management.
Using SHOW NETWORK POLICIES without any additional parameters will display all network policies in the account, which is useful for administrators to review and manage the security configurations pertaining to network access.
Which table function will identify data that was loaded using COPY INTO