What is the maximum Time Travel retention period for a temporary Snowflake table?
90 days
1 day
7 days
45 days
The maximum Time Travel retention period for a temporary Snowflake table is 1 day. This is the standard retention period for temporary tables, which allows for accessing historical data within a 24-hour window
What are the responsibilities of Snowflake's Cloud Service layer? (Choose three.)
Authentication
Resource management
Virtual warehouse caching
Query parsing and optimization
Query execution
Physical storage of micro-partitions
The responsibilities of Snowflake’s Cloud Service layer include authentication (A), which ensures secure access to the platform; resource management (B), which involves allocating and managing compute resources; and query parsing and optimization (D), which improves the efficiency and performance of SQL query execution3.
If 3 size Small virtual warehouse is made up of two servers, how many servers make up a Large warehouse?
4
8
16
32
In Snowflake, each size increase in virtual warehouses doubles the number of servers. Therefore, if a size Small virtual warehouse is made up of two servers, a Large warehouse, which is two sizes larger, would be made up of eight servers (2 servers for Small, 4 for Medium, and 8 for Large)2.
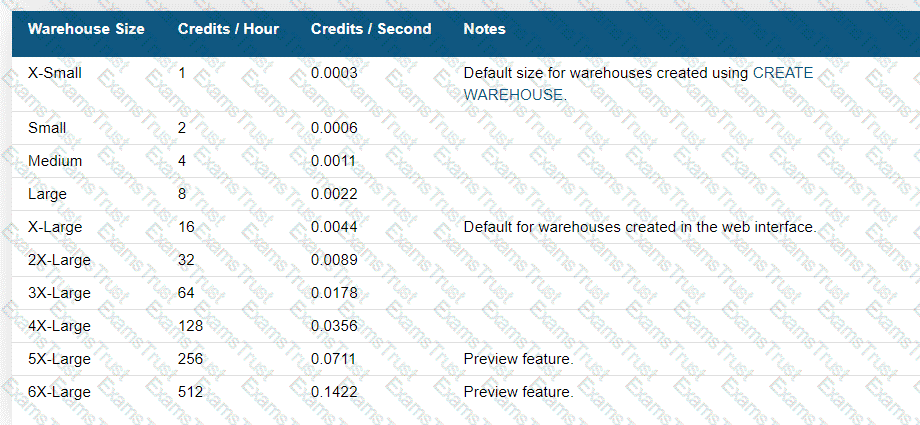
Size specifies the amount of compute resources available per cluster in a warehouse. Snowflake supports the following warehouse sizes:
How long is the Fail-safe period for temporary and transient tables?
There is no Fail-safe period for these tables.
1 day
7 days
31 days
90 days
Temporary and transient tables in Snowflake do not have a Fail-safe period. Once the session ends or the tables are dropped, the data is purged and not recoverable1.
Which Snowflake function will interpret an input string as a JSON document, and produce a VARIANT value?
parse_json()
json_extract_path_text()
object_construct()
flatten
The parse_json() function in Snowflake interprets an input string as a JSON document and produces a VARIANT value containing the JSON document. This function is specifically designed for parsing strings that contain valid JSON information3.
The is the minimum Fail-safe retention time period for transient tables?
1 day
7 days
12 hours
0 days
Transient tables in Snowflake have a minimum Fail-safe retention time period of 0 days. This means that once the Time Travel retention period ends, there is no additional Fail-safe period for transient tables
A running virtual warehouse is suspended.
What is the MINIMUM amount of time that the warehouse will incur charges for when it is restarted?
1 second
60 seconds
5 minutes
60 minutes
When a running virtual warehouse in Snowflake is suspended and then restarted, the minimum amount of time it will incur charges for is 60 seconds2.
When cloning a database, what is cloned with the database? (Choose two.)
Privileges on the database
Existing child objects within the database
Future child objects within the database
Privileges on the schemas within the database
Only schemas and tables within the database
When cloning a database in Snowflake, the clone includes all privileges on the database as well as existing child objects within the database, such as schemas, tables, views, etc. However, it does not include future child objects or privileges on schemas within the database2.
References = [COF-C02] SnowPro Core Certification Exam Study Guide, Snowflake Documentation
Assume there is a table consisting of five micro-partitions with values ranging from A to Z.
Which diagram indicates a well-clustered table?

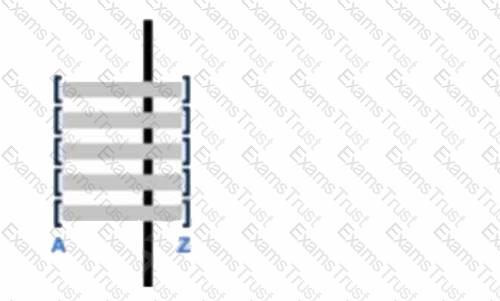

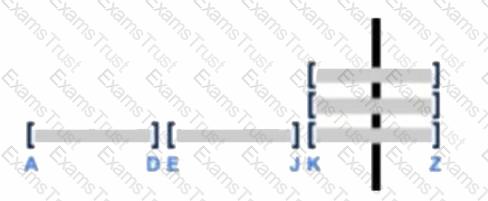
A well-clustered table in Snowflake means that the data is organized in such a way that related data points are stored close to each other within the micro-partitions. This optimizes query performance by reducing the amount of scanned data. The diagram indicated by option C shows a well-clustered table, as it likely represents a more evenly distributed range of values across the micro-partitions1.
References = Snowflake Micro-partitions & Table Clustering
Which Snowflake feature allows a user to substitute a randomly generated identifier for sensitive data, in order to prevent unauthorized users access to the data, before loading it into Snowflake?
External Tokenization
External Tables
Materialized Views
User-Defined Table Functions (UDTF)
The feature in Snowflake that allows a user to substitute a randomly generated identifier for sensitive data before loading it into Snowflake is known as External Tokenization. This process helps to secure sensitive data by ensuring that it is not exposed in its original form, thus preventing unauthorized access3.
Which of the following features are available with the Snowflake Enterprise edition? (Choose two.)
Database replication and failover
Automated index management
Customer managed keys (Tri-secret secure)
Extended time travel
Native support for geospatial data
The Snowflake Enterprise edition includes database replication and failover for business continuity and disaster recovery, as well as extended time travel capabilities for longer data retention periods1.
A company needs to allow some users to see Personally Identifiable Information (PII) while limiting other users from seeing the full value of the PII.
Which Snowflake feature will support this?
Row access policies
Data masking policies
Data encryption
Role based access control
Data masking policies in Snowflake allow for the obfuscation of specific data within a field, enabling some users to see the full data while limiting others. This feature is particularly useful for handling PII, ensuring that sensitive information is only visible to authorized users1.
How does Snowflake Fail-safe protect data in a permanent table?
Fail-safe makes data available up to 1 day, recoverable by user operations.
Fail-safe makes data available for 7 days, recoverable by user operations.
Fail-safe makes data available for 7 days, recoverable only by Snowflake Support.
Fail-safe makes data available up to 1 day, recoverable only by Snowflake Support.
Snowflake’s Fail-safe provides a 7-day period during which data in a permanent table may be recoverable, but only by Snowflake Support, not by user operations3.
True or False: Snowpipe via REST API can only reference External Stages as source.
True
False
Snowpipe via REST API can reference both named internal stages within Snowflake and external stages, such as Amazon S3, Google Cloud Storage, or Microsoft Azure1. This means that Snowpipe is not limited to only external stages as a source for data loading.
References = [COF-C02] SnowPro Core Certification Exam Study Guide, Snowflake Documentation1
Which of the following significantly improves the performance of selective point lookup queries on a table?
Clustering
Materialized Views
Zero-copy Cloning
Search Optimization Service
The Search Optimization Service significantly improves the performance of selective point lookup queries on tables by creating and maintaining a persistent data structure called a search access path, which allows some micro-partitions to be skipped when scanning the table
Snowflake supports the use of external stages with which cloud platforms? (Choose three.)
Amazon Web Services
Docker
IBM Cloud
Microsoft Azure Cloud
Google Cloud Platform
Oracle Cloud
Snowflake supports the use of external stages with Amazon Web Services (AWS), Microsoft Azure Cloud, and Google Cloud Platform (GCP). These platforms allow users to stage data externally and integrate with Snowflake for data loading operations
What are best practice recommendations for using the ACCOUNTADMIN system-defined role in Snowflake? (Choose two.)
Ensure all ACCOUNTADMIN roles use Multi-factor Authentication (MFA).
All users granted ACCOUNTADMIN role must be owned by the ACCOUNTADMIN role.
The ACCOUNTADMIN role must be granted to only one user.
Assign the ACCOUNTADMIN role to at least two users, but as few as possible.
All users granted ACCOUNTADMIN role must also be granted SECURITYADMIN role.
Best practices for using the ACCOUNTADMIN role include ensuring that all users with this role use Multi-factor Authentication (MFA) for added security. Additionally, it is recommended to assign the ACCOUNTADMIN role to at least two users to avoid delays in case of password recovery issues, but to as few users as possible to maintain strict control over account-level operations4.
What is an advantage of using an explain plan instead of the query profiler to evaluate the performance of a query?
The explain plan output is available graphically.
An explain plan can be used to conduct performance analysis without executing a query.
An explain plan will handle queries with temporary tables and the query profiler will not.
An explain plan's output will display automatic data skew optimization information.
An explain plan is beneficial because it allows for the evaluation of how a query will be processed without the need to actually execute the query. This can help in understanding the query’s performance implications and potential bottlenecks without consuming resources that would be used if the query were run
What are common issues found by using the Query Profile? (Choose two.)
Identifying queries that will likely run very slowly before executing them
Locating queries that consume a high amount of credits
Identifying logical issues with the queries
Identifying inefficient micro-partition pruning
Data spilling to a local or remote disk
The Query Profile in Snowflake is used to identify performance issues with queries. Common issues that can be found using the Query Profile include identifying inefficient micro-partition pruning (D) and data spilling to a local or remote disk (E). Micro-partition pruning is related to the efficiency of query execution, and data spilling occurs when the memory is insufficient, causing the query to write data to disk, which can slow down the query performance1.
Why does Snowflake recommend file sizes of 100-250 MB compressed when loading data?
Optimizes the virtual warehouse size and multi-cluster setting to economy mode
Allows a user to import the files in a sequential order
Increases the latency staging and accuracy when loading the data
Allows optimization of parallel operations
Snowflake recommends file sizes between 100-250 MB compressed when loading data to optimize parallel processing. Smaller, compressed files can be loaded in parallel, which maximizes the efficiency of the virtual warehouses and speeds up the data loading process
What are supported file formats for unloading data from Snowflake? (Choose three.)
XML
JSON
Parquet
ORC
AVRO
CSV
The supported file formats for unloading data from Snowflake include JSON, Parquet, and CSV. These formats are commonly used for their flexibility and compatibility with various data processing tools
Which minimum Snowflake edition allows for a dedicated metadata store?
Standard
Enterprise
Business Critical
Virtual Private Snowflake
The Enterprise edition of Snowflake allows for a dedicated metadata store, providing additional features designed for large-scale enterprises
What is the MINIMUM edition of Snowflake that is required to use a SCIM security integration?
Business Critical Edition
Standard Edition
Virtual Private Snowflake (VPS)
Enterprise Edition
The minimum edition of Snowflake required to use a SCIM security integration is the Enterprise Edition. SCIM integrations are used for automated management of user identities and groups, and this feature is available starting from the Enterprise Edition of Snowflake. References: [COF-C02] SnowPro Core Certification Exam Study Guide
What is true about sharing data in Snowflake? (Choose two.)
The Data Consumer pays for data storage as well as for data computing.
The shared data is copied into the Data Consumer account, so the Consumer can modify it without impacting the base data of the Provider.
A Snowflake account can both provide and consume shared data.
The Provider is charged for compute resources used by the Data Consumer to query the shared data.
The Data Consumer pays only for compute resources to query the shared data.
In Snowflake’s data sharing model, any full Snowflake account can both provide and consume shared data. Additionally, the data consumer pays only for the compute resources used to query the shared data. No actual data is copied or transferred between accounts, and shared data does not take up any storage in a consumer account, so the consumer does not pay for data storage1.
References = Introduction to Secure Data Sharing | Snowflake Documentation
What is the following SQL command used for?
Select * from table(validate(t1, job_id => '_last'));
To validate external table files in table t1 across all sessions
To validate task SQL statements against table t1 in the last 14 days
To validate a file for errors before it gets executed using a COPY command
To return errors from the last executed COPY command into table t1 in the current session
The SQL command Select * from table(validate(t1, job_id => '_last')); is used to return errors from the last executed COPY command into table t1 in the current session. It checks the results of the most recent data load operation and provides details on any errors that occurred during that process1.
How many days is load history for Snowpipe retained?
1 day
7 days
14 days
64 days
Snowpipe retains load history for 14 days. This allows users to view and audit the data that has been loaded into Snowflake using Snowpipe within this time frame3.
A Snowflake Administrator needs to ensure that sensitive corporate data in Snowflake tables is not visible to end users, but is partially visible to functional managers.
How can this requirement be met?
Use data encryption.
Use dynamic data masking.
Use secure materialized views.
Revoke all roles for functional managers and end users.
Dynamic data masking is a feature in Snowflake that allows administrators to define masking policies to protect sensitive data. It enables partial visibility of the data to certain roles, such as functional managers, while hiding it from others, like end users
What features that are part of the Continuous Data Protection (CDP) feature set in Snowflake do not require additional configuration? (Choose two.)
Row level access policies
Data masking policies
Data encryption
Time Travel
External tokenization
Data encryption and Time Travel are part of Snowflake’s Continuous Data Protection (CDP) feature set that do not require additional configuration. Data encryption is automatically applied to all files stored on internal stages, and Time Travel allows for querying and restoring data without any extra setup
What are the correct parameters for time travel and fail-safe in the Snowflake Enterprise Edition?
Default Time Travel Retention is set to 0 days.
Maximum Time Travel Retention is 30 days.
Fail Safe retention time is 1 day.
Default Time Travel Retention is set to 1 day.
Maximum Time Travel Retention is 365 days.
Fail Safe retention time is 7 days.
Default Time Travel Retention is set to 0 days.
Maximum Time Travel Retention is 90 days.
Fail Safe retention time is 7 days.
Default Time Travel Retention is set to 1 day.
Maximum Time Travel Retention is 90 days.
Fail Safe retention time is 7 days.
Default Time Travel Retention is set to 7 days.
Maximum Time Travel Retention is 1 day.
Fail Safe retention time is 90 days.
Default Time Travel Retention is set to 90 days.
Maximum Time Travel Retention is 7 days.
Fail Safe retention time is 356 days.
In the Snowflake Enterprise Edition, the default Time Travel retention is set to 1 day, the maximum Time Travel retention can be set up to 90 days, and the Fail-safe retention time is 7 days3.
A user has unloaded data from a Snowflake table to an external stage.
Which command can be used to verify if data has been uploaded to the external stage named my_stage?
view @my_stage
list @my_stage
show @my_stage
display @my_stage
The list @my_stage command in Snowflake can be used to verify if data has been uploaded to an external stage named my_stage. This command provides a list of files that are present in the specified stage2.
What COPY INTO SQL command should be used to unload data into multiple files?
SINGLE=TRUE
MULTIPLE=TRUE
MULTIPLE=FALSE
SINGLE=FALSE
The COPY INTO SQL command with the option SINGLE=FALSE is used to unload data into multiple files. This option allows the data to be split into multiple files during the unload process. References: SnowPro Core Certification COPY INTO SQL command unload multiple files
How long is Snowpipe data load history retained?
As configured in the create pipe settings
Until the pipe is dropped
64 days
14 days
Snowpipe data load history is retained for 64 days. This retention period allows users to review and audit the data load operations performed by Snowpipe over a significant period of time, which can be crucial for troubleshooting and ensuring data integrity.
References:
When reviewing a query profile, what is a symptom that a query is too large to fit into the memory?
A single join node uses more than 50% of the query time
Partitions scanned is equal to partitions total
An AggregateOperacor node is present
The query is spilling to remote storage
When a query in Snowflake is too large to fit into the available memory, it will start spilling to remote storage. This is an indication that the memory allocated for the query is insufficient for its execution, and as a result, Snowflake uses remote disk storage to handle the overflow. This spill to remote storage can lead to slower query performance due to the additional I/O operations required.
References:
Which cache type is used to cache data output from SQL queries?
Metadata cache
Result cache
Remote cache
Local file cache
The Result cache is used in Snowflake to cache the data output from SQL queries. This feature is designed to improve performance by storing the results of queries for a period of time. When the same or similar query is executed again, Snowflake can retrieve the result from this cache instead of re-computing the result, which saves time and computational resources.
References:
Which of the following describes external functions in Snowflake?
They are a type of User-defined Function (UDF).
They contain their own SQL code.
They call code that is stored inside of Snowflake.
They can return multiple rows for each row received
External functions in Snowflake are a special type of User-Defined Function (UDF) that call code executed outside of Snowflake, typically through a remote service. Unlike traditional UDFs, external functions do not contain SQL code within Snowflake; instead, they interact with external services to process data2.
.
Which feature is only available in the Enterprise or higher editions of Snowflake?
Column-level security
SOC 2 type II certification
Multi-factor Authentication (MFA)
Object-level access control
Column-level security is a feature that allows fine-grained control over access to specific columns within a table. This is particularly useful for managing sensitive data and ensuring that only authorized users can view or manipulate certain pieces of information. According to my last update, this feature was available in the Enterprise Edition or higher editions of Snowflake.
References: Based on my internal data as of 2021, column-level security is an advanced feature typically reserved for higher-tiered editions like the Enterprise Edition in data warehousing solutions such as Snowflake.
True or False: A Virtual Warehouse can be resized while suspended.
True
False
Virtual Warehouses in Snowflake can indeed be resized while they are suspended. Resizing a warehouse involves changing the number of compute resources (servers) allocated to it, which can be done to adjust performance and cost. When a warehouse is suspended, it is not currently running any queries, but its definition and metadata remain intact, allowing for modifications like resizing.
What SQL command would be used to view all roles that were granted to user.1?
show grants to user USER1;
show grants of user USER1;
describe user USER1;
show grants on user USER1;
The correct command to view all roles granted to a specific user in Snowflake is SHOW GRANTS TO USER
A virtual warehouse's auto-suspend and auto-resume settings apply to which of the following?
The primary cluster in the virtual warehouse
The entire virtual warehouse
The database in which the virtual warehouse resides
The Queries currently being run on the virtual warehouse
The auto-suspend and auto-resume settings in Snowflake apply to the entire virtual warehouse. These settings allow the warehouse to automatically suspend when it’s not in use, helping to save on compute costs. When queries or tasks are submitted to the warehouse, it can automatically resume operation. This functionality is designed to optimize resource usage and cost-efficiency.
References:
True or False: Loading data into Snowflake requires that source data files be no larger than 16MB.
True
False
Snowflake does not require source data files to be no larger than 16MB. In fact, Snowflake recommends that for optimal load performance, data files should be roughly 100-250 MB in size when compressed. However, it is not recommended to load very large files (e.g., 100 GB or larger) due to potential delays and wasted credits if errors occur. Smaller files should be aggregated to minimize processing overhead, and larger files should be split to distribute the load among compute resources in an active warehouse.
References: Preparing your data files | Snowflake Documentation
A user has unloaded data from Snowflake to a stage
Which SQL command should be used to validate which data was loaded into the stage?
list @file__stage
show @file__stage
view @file__stage
verify @file__stage
The list command in Snowflake is used to validate and display the list of files in a specified stage. When a user has unloaded data to a stage, running the list @file__stage command will show all the files that have been uploaded to that stage, allowing the user to verify the data that was unloaded.
References:
True or False: It is possible for a user to run a query against the query result cache without requiring an active Warehouse.
True
False
Snowflake’s architecture allows for the use of a query result cache that stores the results of queries for a period of time. If the same query is run again and the underlying data has not changed, Snowflake can retrieve the result from this cache without needing to re-run the query on an active warehouse, thus saving on compute resources.
A user has an application that writes a new Tile to a cloud storage location every 5 minutes.
What would be the MOST efficient way to get the files into Snowflake?
Create a task that runs a copy into operation from an external stage every 5 minutes
Create a task that puts the files in an internal stage and automate the data loading wizard
Create a task that runs a GET operation to intermittently check for new files
Set up cloud provider notifications on the Tile location and use Snowpipe with auto-ingest
The most efficient way to get files into Snowflake, especially when new files are being written to a cloud storage location at frequent intervals, is to use Snowpipe with auto-ingest. Snowpipe is Snowflake’s continuous data ingestion service that loads data as soon as it becomes available in a cloud storage location. By setting up cloud provider notifications, Snowpipe can be triggered automatically whenever new files are written to the storage location, ensuring that the data is loaded into Snowflake with minimal latency and without the need for manual intervention or scheduling frequent tasks.
References:
True or False: Reader Accounts are able to extract data from shared data objects for use outside of Snowflake.
True
False
Reader accounts in Snowflake are designed to allow users to read data shared with them but do not have the capability to extract data for use outside of Snowflake. They are intended for consuming shared data within the Snowflake environment only.
What are value types that a VARIANT column can store? (Select TWO)
STRUCT
OBJECT
BINARY
ARRAY
CLOB
A VARIANT column in Snowflake can store semi-structured data types. This includes:
The VARIANT data type is specifically designed to handle semi-structured data like JSON, Avro, ORC, Parquet, or XML, allowing for the storage of nested and complex data structures.
References:
Which Snowflake feature is used for both querying and restoring data?
Cluster keys
Time Travel
Fail-safe
Cloning
Snowflake’s Time Travel feature is used for both querying historical data in tables and restoring and cloning historical data in databases, schemas, and tables3. It allows users to access historical data within a defined period (1 day by default, up to 90 days for Snowflake Enterprise Edition) and is a key feature for data recovery and management. References: [COF-C02] SnowPro Core Certification Exam Study Guide
A user needs to create a materialized view in the schema MYDB.MYSCHEMA.
Which statements will provide this access?
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO ROLE MYROLE;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO USER USER1;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO USER1;
GRANT ROLE MYROLE TO USER USER1;
CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO MYROLE;
In Snowflake, to create a materialized view, the user must have the necessary privileges on the schema where the view will be created. These privileges are granted through roles, not directly to individual users. Therefore, the correct process is to grant the role to the user and then grant the privilege to create the materialized view to the role itself.
The statement GRANT ROLE MYROLE TO USER USER1; grants the specified role to the user, allowing them to assume that role and exercise its privileges. The subsequent statement CREATE MATERIALIZED VIEW ON SCHEMA MYDB.MYSCHEMA TO MYROLE; grants the privilege to create a materialized view within the specified schema to the role MYROLE. Any user who has been granted MYROLE can then create materialized views in MYDB.MYSCHEMA.
References:
What are ways to create and manage data shares in Snowflake? (Select TWO)
Through the Snowflake web interface (Ul)
Through the DATA_SHARE=TRUE parameter
Through SQL commands
Through the enable__share=true parameter
Using the CREATE SHARE AS SELECT * TABLE command
Data shares in Snowflake can be created and managed through the Snowflake web interface, which provides a user-friendly graphical interface for various operations. Additionally, SQL commands can be used to perform these tasks programmatically, offering flexibility and automation capabilities123.
A sales table FCT_SALES has 100 million records.
The following Query was executed
SELECT COUNT (1) FROM FCT__SALES;
How did Snowflake fulfill this query?
Query against the result set cache
Query against a virtual warehouse cache
Query against the most-recently created micro-partition
Query against the metadata excite
Snowflake is designed to optimize query performance by utilizing metadata for certain types of queries. When executing a COUNT query, Snowflake can often fulfill the request by accessing metadata about the table’s row count, rather than scanning the entire table or micro-partitions. This is particularly efficient for large tables like FCT_SALES with a significant number of records. The metadata layer maintains statistics about the table, including the row count, which enables Snowflake to quickly return the result of a COUNT query without the need to perform a full scan.
References:
Which copy INTO command outputs the data into one file?
SINGLE=TRUE
MAX_FILE_NUMBER=1
FILE_NUMBER=1
MULTIPLE=FAISE
The COPY INTO command in Snowflake can be configured to output data into a single file by setting the MAX_FILE_NUMBER option to 1. This option limits the number of files generated by the command, ensuring that only one file is created regardless of the amount of data being exported.
References:
Which command can be used to stage local files from which Snowflake interface?
SnowSQL
Snowflake classic web interface (Ul)
Snowsight
.NET driver
SnowSQL is the command-line client for Snowflake that allows users to execute SQL queries and perform all DDL and DML operations, including staging files for bulk data loading. It is specifically designed for scripting and automating tasks.
References:
What happens to the underlying table data when a CLUSTER BY clause is added to a Snowflake table?
Data is hashed by the cluster key to facilitate fast searches for common data values
Larger micro-partitions are created for common data values to reduce the number of partitions that must be scanned
Smaller micro-partitions are created for common data values to allow for more parallelism
Data may be colocated by the cluster key within the micro-partitions to improve pruning performance
When a CLUSTER BY clause is added to a Snowflake table, it specifies one or more columns to organize the data within the table’s micro-partitions. This clustering aims to colocate data with similar values in the same or adjacent micro-partitions. By doing so, it enhances the efficiency of query pruning, where the Snowflake query optimizer can skip over irrelevant micro-partitions that do not contain the data relevant to the query, thereby improving performance.
References:
Which of the following commands cannot be used within a reader account?
CREATE SHARE
ALTER WAREHOUSE
DROP ROLE
SHOW SCHEMAS
DESCRBE TABLE
In Snowflake, a reader account is a type of account that is intended for consuming shared data rather than performing any data management or DDL operations. The CREATE SHARE command is used to share data from your account with another account, which is not a capability provided to reader accounts. Reader accounts are typically restricted from creating shares, as their primary purpose is to read shared data rather than to share it themselves.
References:
Which command is used to unload data from a Snowflake table into a file in a stage?
COPY INTO
GET
WRITE
EXTRACT INTO
The COPY INTO command is used in Snowflake to unload data from a table into a file in a stage. This command allows for the export of data from Snowflake tables into flat files, which can then be used for further analysis, processing, or storage in external systems.
References:
What is the recommended file sizing for data loading using Snowpipe?
A compressed file size greater than 100 MB, and up to 250 MB
A compressed file size greater than 100 GB, and up to 250 GB
A compressed file size greater than 10 MB, and up to 100 MB
A compressed file size greater than 1 GB, and up to 2 GB
For data loading using Snowpipe, the recommended file size is a compressed file greater than 10 MB and up to 100 MB. This size range is optimal for Snowpipe’s continuous, micro-batch loading process, allowing for efficient and timely data ingestion without overwhelming the system with files that are too large or too small.
References:
The fail-safe retention period is how many days?
1 day
7 days
45 days
90 days
Fail-safe is a feature in Snowflake that provides an additional layer of data protection. After the Time Travel retention period ends, Fail-safe offers a non-configurable 7-day period during which historical data may be recoverable by Snowflake. This period is designed to protect against accidental data loss and is not intended for customer access.
References: Understanding and viewing Fail-safe | Snowflake Documentation
In the query profiler view for a query, which components represent areas that can be used to help optimize query performance? (Select TWO)
Bytes scanned
Bytes sent over the network
Number of partitions scanned
Percentage scanned from cache
External bytes scanned
In the query profiler view, the components that represent areas that can be used to help optimize query performance include ‘Bytes scanned’ and ‘Number of partitions scanned’. ‘Bytes scanned’ indicates the total amount of data the query had to read and is a direct indicator of the query’s efficiency. Reducing the bytes scanned can lead to lower data transfer costs and faster query execution. ‘Number of partitions scanned’ reflects how well the data is clustered; fewer partitions scanned typically means better performance because the system can skip irrelevant data more effectively.
References:
What Snowflake features allow virtual warehouses to handle high concurrency workloads? (Select TWO)
The ability to scale up warehouses
The use of warehouse auto scaling
The ability to resize warehouses
Use of multi-clustered warehouses
The use of warehouse indexing
Snowflake’s architecture is designed to handle high concurrency workloads through several features, two of which are particularly effective:
These features ensure that Snowflake can manage varying levels of demand without manual intervention, providing a seamless experience even during peak usage.
References:
Which of the following Snowflake capabilities are available in all Snowflake editions? (Select TWO)
Customer-managed encryption keys through Tri-Secret Secure
Automatic encryption of all data
Up to 90 days of data recovery through Time Travel
Object-level access control
Column-level security to apply data masking policies to tables and views
In all Snowflake editions, two key capabilities are universally available:
These features are part of Snowflake’s commitment to security and governance, and they are included in every edition of the Snowflake Data Cloud.
References:
Will data cached in a warehouse be lost when the warehouse is resized?
Possibly, if the warehouse is resized to a smaller size and the cache no longer fits.
Yes. because the compute resource is replaced in its entirety with a new compute resource.
No. because the size of the cache is independent from the warehouse size
Yes. became the new compute resource will no longer have access to the cache encryption key
When a Snowflake virtual warehouse is resized, the data cached in the warehouse is not lost. This is because the cache is maintained independently of the warehouse size. Resizing a warehouse, whether scaling up or down, does not affect the cached data, ensuring that query performance is not impacted by such changes.
References:
Which semi-structured file formats are supported when unloading data from a table? (Select TWO).
ORC
XML
Avro
Parquet
JSON
Semi-structured
JSON, Parquet
Snowflake supports unloading data in several semi-structured file formats, including Parquet and JSON. These formats allow for efficient storage and querying of semi-structured data, which can be loaded directly into Snowflake tables without requiring a predefined schema12.
&text=Delimited%20(CSV%2C%20TSV%2C%20etc.)
Which of the following is a valid source for an external stage when the Snowflake account is located on Microsoft Azure?
An FTP server with TLS encryption
An HTTPS server with WebDAV
A Google Cloud storage bucket
A Windows server file share on Azure
In Snowflake, when the account is located on Microsoft Azure, a valid source for an external stage can be an Azure container or a folder path within an Azure container. This includes Azure Blob storage which is accessible via the azure:// endpoint. A Windows server file share on Azure, if configured properly, can be a valid source for staging data files for Snowflake. Options A, B, and C are not supported as direct sources for an external stage in Snowflake on Azure12. References: [COF-C02] SnowPro Core Certification Exam Study Guide
What happens when a Snowflake user changes the data retention period at the schema level?
All child objects will retain data for the new retention period.
All child objects that do not have an explicit retention period will automatically inherit the new retention period.
All child objects with an explicit retention period will be overridden with the new retention period.
All explicit child object retention periods will remain unchanged.
When the data retention period is changed at the schema level, all child objects that do not have an explicit retention period set will inherit the new retention period from the schema4.
For which use cases is running a virtual warehouse required? (Select TWO).
When creating a table
When loading data into a table
When unloading data from a table
When executing a show command
When executing a list command
Running a virtual warehouse is required when loading data into a table and when unloading data from a table because these operations require compute resources that are provided by the virtual warehouse23.
Which type of loop requires a BREAK statement to stop executing?
FOR
LOOP
REPEAT
WHILE
The LOOP type of loop in Snowflake Scripting does not have a built-in termination condition and requires a BREAK statement to stop executing4.
What step can reduce data spilling in Snowflake?
Using a larger virtual warehouse
Increasing the virtual warehouse maximum timeout limit
Increasing the amount of remote storage for the virtual warehouse
Using a common table expression (CTE) instead of a temporary table
To reduce data spilling in Snowflake, using a larger virtual warehouse is effective because it provides more memory and local disk space, which can accommodate larger data operations and minimize the need to spill data to disk or remote storage1. References: [COF-C02] SnowPro Core Certification Exam Study Guide
Which commands can only be executed using SnowSQL? (Select TWO).
COPY INTO
GET
LIST
PUT
REMOVE
The LIST and PUT commands are specific to SnowSQL and cannot be executed in the web interface or other SQL clients. LIST is used to display the contents of a stage, and PUT is used to upload files to a stage. References: [COF-C02] SnowPro Core Certification Exam Study Guide
When enabling access to unstructured data, which URL permits temporary access to a staged file without the need to grant privileges to the stage or to issue access tokens?
File URL
Scoped URL
Relative URL
Pre-Signed URL
A Scoped URL permits temporary access to a staged file without the need to grant privileges to the stage or to issue access tokens. It provides a secure way to share access to files stored in Snowflake
How is unstructured data retrieved from data storage?
SQL functions like the GET command can be used to copy the unstructured data to a location on the client.
SQL functions can be used to create different types of URLs pointing to the unstructured data. These URLs can be used to download the data to a client.
SQL functions can be used to retrieve the data from the query results cache. When the query results are output to a client, the unstructured data will be output to the client as files.
SQL functions can call on different web extensions designed to display different types of files as a web page. The web extensions will allow the files to be downloaded to the client.
Unstructured data stored in Snowflake can be retrieved by using SQL functions to generate URLs that point to the data. These URLs can then be used to download the data directly to a client
A user wants to access files stored in a stage without authenticating into Snowflake. Which type of URL should be used?
File URL
Staged URL
Scoped URL
Pre-signed URL
A Pre-signed URL should be used to access files stored in a Snowflake stage without requiring authentication into Snowflake. Pre-signed URLs are simple HTTPS URLs that provide temporary access to a file via a web browser, using a pre-signed access token. The expiration time for the access token is configurable, and this type of URL allows users or applications to directly access or download the files without needing to authenticate into Snowflake5.
References: [COF-C02] SnowPro Core Certification Exam Study Guide
A permanent table and temporary table have the same name, TBL1, in a schema.
What will happen if a user executes select * from TBL1 ;?
The temporary table will take precedence over the permanent table.
The permanent table will take precedence over the temporary table.
An error will say there cannot be two tables with the same name in a schema.
The table that was created most recently will take precedence over the older table.
In Snowflake, if a temporary table and a permanent table have the same name within the same schema, the temporary table takes precedence over the permanent table within the session where the temporary table was created4.
What does SnowCD help Snowflake users to do?
Copy data into files.
Manage different databases and schemas.
Troubleshoot network connections to Snowflake.
Write SELECT queries to retrieve data from external tables.
SnowCD is a connectivity diagnostic tool that helps users troubleshoot network connections to Snowflake. It performs a series of checks to evaluate the network connection and provides suggestions for resolving any issues4.
What is a directory table in Snowflake?
A separate database object that is used to store file-level metadata
An object layered on a stage that is used to store file-level metadata
A database object with grantable privileges for unstructured data tasks
A Snowflake table specifically designed for storing unstructured files
A directory table in Snowflake is an object layered on a stage that is used to store file-level metadata. It is not a separate database object but is conceptually similar to an external table because it stores metadata about the data files in the stage5.
A column named "Data" contains VARIANT data and stores values as follows:

How will Snowflake extract the employee's name from the column data?
Data:employee.name
DATA:employee.name
data:Employee.name
data:employee.name
In Snowflake, to extract a specific value from a VARIANT column, you use the column name followed by a colon and then the key. The keys are case-sensitive. Therefore, to extract the employee’s name from the “Data” column, the correct syntax is data:employee.name.
Which VALIDATION_MODE value will return the errors across the files specified in a COPY command, including files that were partially loaded during an earlier load?
RETURN_-1_R0WS
RETURN_n_ROWS
RETURN_ERRORS
RETURN ALL ERRORS
The RETURN_ERRORS value in the VALIDATION_MODE option of the COPY command instructs Snowflake to validate the data files and return errors encountered across all specified files, including those that were partially loaded during an earlier load2. References: [COF-C02] SnowPro Core Certification Exam Study Guide
What tasks can an account administrator perform in the Data Exchange? (Select TWO).
Add and remove members.
Delete data categories.
Approve and deny listing approval requests.
Transfer listing ownership.
Transfer ownership of a provider profile.
An account administrator in the Data Exchange can perform tasks such as adding and removing members and approving or denying listing approval requests. These tasks are part of managing the Data Exchange and ensuring that only authorized listings and members are part of it12.
Which command is used to unload data from a Snowflake database table into one or more files in a Snowflake stage?
CREATE STAGE
COPY INTO